
Have you ever wondered how Amazon can recommend products you thought you wanted but never searched for? If you’ve ever shopped on the platform, you’re likely to have encountered its persistent product recommendations. It’s the same with your playlist on Spotify and your YouTube video recommendations.
These are examples of deep learning in action.
In this article, we’ll explore how deep learning is fueling the future of business and its key advantages. Let’s start by understanding what deep learning is.
What Is Deep Learning?
Deep learning is a branch of machine learning (ML) that mimics the functioning of the human brain to find correlations and patterns by processing data with a specified logical structure. Also referred to as deep neural networks, deep learning uses multiple hidden layers in the neural network as opposed to traditional neural networks that only contain a handful of hidden layers.
Deep learning algorithms map inputs to already learned data to deliver an accurate output. The concept underpinning this technology is very similar to how our brains function (biological neural networks). We compare new information with known information to arrive at a conclusion.
Deep learning models are trained by using large sets of labeled data and neural network architectures that automate feature learning without the need for manual extraction.
The History of Deep Learning
So, where did this all originate? Deep learning first gained popularity in academic circles as machine learning researchers looked to expand the scope of machine learning using larger datasets and more computation times. However, deep learning was viewed with skepticism in the AI community for the longest time due to its shortcomings, particularly the lack of large enough datasets for training and lower available processing power in computers.
All of that changed in 2012. Two researchers from the University of Toronto made history at ImageNet – an annual competition where contestants develop computer vision software based on large datasets, by developing an algorithm with an error rate of 15.3%. This was a huge improvement over the benchmark.
In the business community, Amazon had quietly been working on refining its item-to-item collaborative filtering technology that relied on massive behavioral and catalogue datasets to deliver recommendations in real time.
In 2014, Amazon tasked a team in the personalization group to design a new recommendation algorithm for Prime Video based on a neural network called an autoencoder. From a business standpoint, Amazon’s recommendation engine paid off big time.

Amazon’s recommendation engine has enabled the e-commerce giant to increase the average order value per cart and offer an unparalleled user experience. By 2013, Amazon was already generating 35% of its revenue from its recommendation engine. The business impact? Amazon’s stock grew by a whopping 1,200% between 2013 and 2021.
Machine Learning and Deep Learning: What’s the Difference?
While both technologies use data for feature learning, a significant differentiator between ML and deep learning is the latter’s ability to scale with data. ML algorithms tend to plateau in performance after training with large data sets and then diminishing returns kick in. On the other hand, deep learning models perform better as training datasets increase in volume.
The illustration below by Andrew Ng, founder of Google Brain and the former Chief Scientist at Baidu, provides an accurate representation of the difference between traditional machine learning models and deep learning.
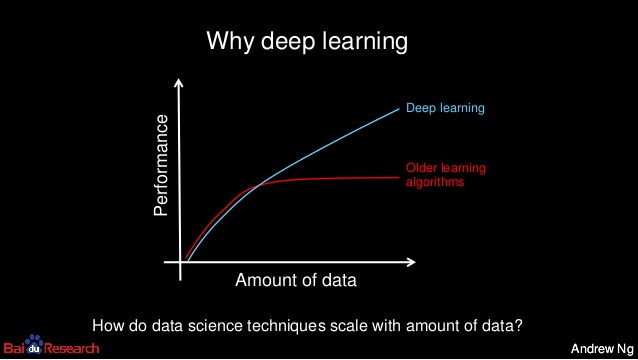
With deep learning, feature extraction and modeling steps are automatically performed after data training while machine learning requires data scientists or users to extract and create features. Traditional ML models cannot be used to solve problems that deep learning models can solve.
Deep Learning: Real-World Applications and Examples
Deep learning is the closest we’ve gotten to creating real machine intelligence. It underpins all recent innovations in artificial intelligence such as smart voice assistants, recommendation systems, image recognition, and even self-driving cars.
In the age of Big Data, deep learning is crucial for knowledge application and knowledge-based predictions. Let’s take a look at the top three use cases of deep learning:
- Computer vision: Computer vision powers self-driving cars, drones, and a host of biometric processes by comprehending a visual environment and deciphering its context. It leverages deep learning models to identify and classify images by using predefined, labeled categories.
- Natural language processing (NLP): NLP algorithms analyze and interpret human language inputs in textual or verbal formats. Key applications include text classification, sentiment analysis, translation, speech recognition, and more. A few real-world examples of NLP are smart virtual assistants (Siri, Alexa, Cortana), adaptive email filters, and chatbots.
- Predictive modeling: Deep learning algorithms power most intelligent recommendation engines using a combination of predictive modeling and collaborative filtering. Predictive modeling tackles a crucial problem with collaborative filtering: the cold start problem. This is where fresh content that users haven’t engaged with cannot accurately be placed in the recommendation matrix. Since there is no engagement with this new content, users are unlikely to try it out. This creates a vicious cycle where new content goes unnoticed and gains little traction. Examples of predictive models powered by artificial neural networks (ANN) or convolutional neural networks (CNN) can be found across leading video streaming and e-commerce platforms.

Deep learning has found acceptance across all major business functions from customer service to cybersecurity and marketing. It's driving the new age of personalization, fraud detection, forecasting, and even supply chain optimization.
Top 7 Advantages of Deep Learning Over Classical ML Models
We’ve already touched upon how deep learning is more scalable than its classical ML counterparts. This translates to a massive opportunity for businesses looking to leverage the technology to deliver high-performance outcomes. Research firms predict that the deep learning market could be worth nearly $100 billion by 2028 driven by data mining, sentiment analytics, recommendations, and personalization.
So, what’s behind this massive growth? Why has deep learning emerged as the AI of choice for forward-looking businesses? Let’s find out!
1. Feature Generation Automation
Deep learning algorithms can generate new features from among a limited number located in the training dataset without additional human intervention. This means deep learning can perform complex tasks that often require extensive feature engineering.
For businesses, this means faster application or technology rollouts that deliver superior accuracy.
2. Works Well With Unstructured Data
One of the biggest draws of deep learning is its ability to work with unstructured data. In the business context, this becomes particularly relevant when you consider that the majority of business data is unstructured. Text, images, and voice are some of the most common data formats that businesses use. Classical ML algorithms are limited in their ability to analyze unstructured data, meaning this wealth of information often goes untapped. And here’s where deep learning promises to make the most impact.
Training deep learning networks with unstructured data and appropriate labeling can help businesses optimize virtually every function from marketing and sales to finance.
3. Better Self-Learning Capabilities
The multiple layers in deep neural networks allow models to become more efficient at learning complex features and performing more intensive computational tasks, i.e., execute many complex operations simultaneously. It outshines machine learning in machine perception tasks (aka the ability to make sense of inputs like images, sounds, and video like a human would) that involve unstructured datasets.
This is due to deep learning algorithms' ability to eventually learn from its own errors. It can verify the accuracy of its predictions/outputs and make necessary adjustments. On the other hand, classical machine learning models require varying degrees of human intervention to determine the accuracy of output.
What’s more? Deep learning’s performance is directly proportional to the volume of training datasets. So, the larger the datasets, the more accuracy.
4. Supports Parallel and Distributed Algorithms
A typical neural network or deep learning model takes days to learn the parameters that define the model. Parallel and distributed algorithms address this pain point by allowing deep learning models to be trained much faster. Models can be trained using local training (use one machine to train the model), with GPUs, or a combination of both.
However, the sheer volume of the training datasets involved could mean that storing it in a single machine becomes impossible. And that’s where data parallelism comes in. With data or the model itself being distributed across multiple machines, training is more effective.
Parallel and distributed algorithms allow deep learning models to be trained at scale. For instance, if you were to train a model on a single computer, it could take up to 10 days to run through all the data. On the other hand, parallel algorithms can be distributed across multiple systems/computers to complete the training in less than a day. Depending on the volume of your training dataset and GPU computing power, you could use as few as two or three computers to over 20 computers to complete the training within a day.
5. Cost Effectiveness
While training deep learning models can be cost-intensive, once trained, it can help businesses cut down on unnecessary expenditure. In industries such as manufacturing, consulting, or even retail, the cost of an inaccurate prediction or product defect is massive. It often outweighs the costs of training deep learning models.
Deep learning algorithms can factor in variation across learning features to reduce error margins dramatically across industries and verticals. This is particularly true when you compare the limitations of the classical machine learning model to deep learning algorithms.
6. Advanced Analytics
Deep learning, when applied to data science, can offer better and more effective processing models. Its ability to learn unsupervised drives continuous improvement in accuracy and outcomes. It also offers data scientists with more reliable and concise analysis results.
The technology powers most prediction software today with applications ranging from marketing to sales, HR, finance, and more. If you use a financial forecasting tool, chances are that it uses a deep neural network. Similarly, intelligent sales and marketing automation suites also leverage deep learning algorithms to make predictions based on historical data.
7. Scalability
Deep learning is highly scalable due to its ability to process massive amounts of data and perform a lot of computations in a cost- and time-effective manner. This directly impacts productivity (faster deployment/rollouts) and modularity and portability (trained models can be used across a range of problems).
For instance, Google Cloud’s AI platform prediction allows you to run your deep neural network at scale on the cloud. So, in addition to better model organization and versioning, you can also leverage Google’s cloud infrastructure to scale batch prediction. This then improves efficiency by automatically scaling the number of nodes in use based on request traffic.
Take Advantage of Deep Learning
For all that deep learning has to offer, it requires massive computational power and training datasets that limit its ability to be applied across new domains. It remains a black box — we still have little visibility into how deep learning models make their predictions.
However, it also represents how far we’ve come to achieving real machine intelligence. The very limitations that plague the technology have also given rise to increasing research in explainable AI. For the problems we are looking to solve in business and automation, deep learning is still the best bet.
Interested to see what deep learning can do for your business? Let’s talk about how we can apply deep learning to increase efficiency and create tangible bottom-line impact.
Contact us to learn more.
