It’s been nearly four years since data analytics became the dominant theme across major industry circuits like conferences, seminars, and consulting. Data has been described as the new oil, new soil, the next big bang, and even the force behind a new business revolution.
In 2021, it’s still as relevant for businesses as ever.
Businesses are still looking for effective ways to transform their data assets into actionable insights that produce business ROI and reduce costs. While the idea might seem straightforward, there’s a significant gap between the vision and real business processes.
Over the past four years, we’ve witnessed the consumerization of concepts like predictive analytics, artificial intelligence, and conversational interfaces — all powered by data. However, despite the hype, the reality is that most businesses still struggle to leverage data in a meaningful way.
Let’s consider the data and analytics maturity model* for organizations:
While organizations have had some success with the first three steps in the maturity model, building analytical models, and data management and integration remain key challenges.
In this article we’ll look at how you can bridge the data analytics maturity gap by integrating and managing your data with an enterprise data warehouse (EDW).
What Is an Enterprise Data Warehouse?
An enterprise data warehouse (EDW) is a central repository of big data for an enterprise. Big data in this context includes everything from customer data to enterprise process-related data and even employee data. This data is typically captured using multiple systems like ERPs, CRMs, financial software, physical forms, and other data sources available to an enterprise.
What makes an enterprise data warehouse different from your run-of-the-mill database or data warehouse is scale and architecture. Databases are almost exclusive to business functions and house a very specific type of data.
So, your marketing team uses a customer database to promote your product or service while your finance team will use a completely different database. Similarly, other business units such as human resources, supply chain and logistics, IT, and customer support may use their own dedicated databases to run day-to-day operations.
All data warehouses have one feature in common — they ingest data, transform it, move it, and render it to the end-user. However, with enterprise data warehouses, the complexity of the architecture is much higher due to the sheer volume of data available.
It’s precisely because of this that most EDWs have separate domain-specific datasets bolted on, enabling end-users to run specific queries related to business units and functions.
Features of Enterprise Data Warehouses
To understand what makes an enterprise data warehouse a warehouse, we must first look at some key features that differentiate an EDW from a regular database or data warehouse.
EDW Is Home to AllOrganizational Data
It’s the ultimate data storehouse for an organization. It hosts data from all your business functions and all the historical data related to the organization.
It Helps Users Identify Data Sources
EDW offers a dedicated infrastructure that helps users manage the flow of data from disparate sources and software solutions within the organization.
Every employee interaction, customer interaction, and financial transaction generates new data that flows into the EDW, which organizes this data by source and provides the best approximation of the original data source.
It Stores Structured Data
All EDWs host structured datasets to enable end-users to perform queries via business intelligence (BI) interfaces and run reports for analysis and visualization. This is also a major differentiating feature between an EDW and a data lake.
Data lakes typically store unstructured data for further manipulation and analysis. The advantage of an EDW over a data lake is that anyone from the organization can query data from an EDW while data lakes require specialized data science skills for data manipulation and analysis.
It Hosts Subject-Specific Data
The key function of an EDW is its ability to understand what function or business unit a particular dataset relates to. The data in an EDW is structured around a specific subject — a data model.
For instance, data engineers may tag HR data or employee data with metadata to identify data sources for each data piece. So, an HR professional looking to analyze turnover rate will look at the HR data, which will have data streams flowing in from the organization’s applicant tracking system (ATS), human resource information system (HRIS), and attendance and payroll software.
It’s Non-Volatile
Operational databases allow users to erase past data or overwrite it. However, EDWs are a non-volatile database, meaning data is never deleted from it — at least not by end-users.
Because all data within an EDW is historical data that describes past events, it’s never meant to be erased. Users can manipulate, modify, or update data and data sources, but they can’t delete any data.
The intention behind designing EDWs as non-volatile databases is that accurate analysis is completely reliant on historical data. So, the larger and more detailed the datasets are, the more accurate the analysis is.
3 Common Types of Enterprise Data Warehouse (EDW)
Organizations have unique data analytics needs — bespoke EDWs can be designed to address industry specific analytics requirements, analytical complexities, security requirements, data depth, and budgets. However, most EDW can be classified into three broad categories:
Classic Data Warehouse
A classic EDW features dedicated hardware and software. Classic EDWs are also referred to as on-premise EDWs. With all data residing physically within the organization, you don’t need to develop additional integration capabilities between multiple databases.
Instead, classic EDWs can connect with multiple data sources through APIs to create a regular data flow stream. Data quality management and transformation takes place in dedicated staging areas or within the EDW itself.
Classic EDWs are considered superior to their virtual counterparts because they have fewer abstraction layers (hidden layers) that also make it easier for data scientists and engineers to manage data flow for both processing and reporting.
However, a classic EDW is far from perfect. It requires expensive technological infrastructure in terms of both hardware and software, and you need a group of highly skilled data engineers and DevOps specialists to successfully deploy it.
Who should use it? Classic EDWs are best suited for organizations looking for a more customized EDW. Classic EDW can be adapted into multiple architectural styles depending on business and industry needs.
Virtual Data Warehouse
A virtual data warehouse is a collection of multiple databases connected virtually. It can be queried as a single system.
This is a relatively straightforward approach to managing your business data. All the data resides across multiple data sources but can still act as a single database for the purposes of manipulation and analytics.
Virtual EDWs typically work better with smaller datasets and require constant hardware and software monitoring. Another drawback with virtual EDWs is that complex queries may become time consuming as the system will need to tap into multiple databases to pull up relevant data.
Who should use it? Virtual EDWs are ideal for businesses dealing with standardized raw data that doesn’t require complex analytics. Businesses early in the analytics maturity curve — with limited BI needs or capabilities — would benefit from a virtual EDW.
Cloud Data Warehouse
Over the past few years cloud-based data warehouses or Warehouse-as-a-Service (WAAS) has emerged as an alternative to traditional on-premise and virtual warehouses. Cloud EDWs offer fully-managed, scalable warehousing as a part of their larger BI offering. Certain EDWs like Snowflake also offer standalone EDW solutions.
Cloud EDW architecture and functionalities are similar to other cloud-based services, meaning you don’t have to maintain any infrastructure or tooling. Pricing is typically based on the amount of data storage and analytics complexity you need.
Cloud EDWs are popular because they’ve democratized BI and analytics for organizations and businesses of all sizes. You only pay for what you want.
However, data security is a key concern when it comes to cloud EDWs. Most cloud EDW offerings — including Amazon Redshift, IBM Db2, Google BigQuery, Snowflake, and Microsoft Azure SQL Data Warehouse — provide comprehensive security capabilities or follow best-practices in data security. We recommend checking the potential service provider’s experience and expertise in data security when evaluating solutions.
Who should use it? Cloud EDWs are the best option for organizations and businesses of all sizes. If you need a plug-and-play setup with managed data integration, EDW maintenance, and BI support, cloud EDWs are for you.
Enterprise Data Warehouse Architecture and Real-World Applications
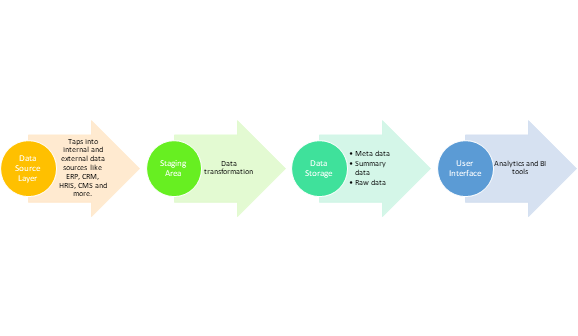
At their core, all enterprise data warehouses have three key components: a raw data layer (data sources), warehousing ecosystem (where data transformation and storage take place), and finally the user interface (BI tools and analytics solutions).
Before we look at enterprise data warehouse architecture in greater detail, it’s important to understand what each of these components will help you achieve.
The image above describes basic enterprise data warehouse architecture, where steps two and three outline the warehousing ecosystem. The warehousing ecosystem is powered by an extract, transform, and load process, also referred to as ETL or ELT.
ETL is the tooling that enables raw business data sources to integrate and communicate with the EDW. ETL is also crucial for performing data manipulation before transferring it to the data warehouse.
Once the data is loaded into the warehouse, it can be cleaned, standardized, and dimensionalized for further data analysis. And this cleaning, standardization, dimensionalization determine the architectural complexity of an EDW.
Let’s take a look at some of the most common approaches to enterprise data warehouse architecture from a business perspective.
One-Tier Architecture
A single-tier architecture is the most basic form of data warehousing. A one-tier EDW typically means that your databases are directly connected to the analytical interfaces where end-users can query information. However, directly connecting your EDW to analytical and BI tools can lead to a few challenges:
Slower processing: Considering that a data warehouse needs at least 100Gb of storage to qualify as a warehouse, adding a BI or analytics layer directly on top can result in inaccurate query results and slower processing.
Needs precise inputs: Querying data right from the data warehouse means your queries need to be very precise in order to get the desired output. This adds complexity to data presentation.
Limited flexibility: With your enterprise data warehouse directly connected to the BI and analytics layer, you have limited analytical capabilities and flexibility. You may only be able to perform very specific queries and work with a limited number of models. This also translates to reduced reporting complexity.
You can supplement a one-tier data warehouse with low-level instances to improve data access and run more complex queries.
Two-Tier Architecture
Two-tier architecture features a data mart between the user interface and EDW. A data mart is a low-level database that only houses domain-specific information. It houses business function-specific data that makes it easier for the EDW to run queries effectively.
Two-tier architecture delivers better output accuracy and faster processing times because business-domain-specific data is already organized at the data mart level.
Building a data mart layer requires additional resources to develop the hardware and integrate your databases with the EDW. The data mart layer also improves the overall security of your EDW because end-users will only be able to access domain-specific data.
Three-Tier Architecture
EDWs with a three-tier architecture feature an online analytical processing (OLAP) cube on top of the data mart layer. An OLAP cube is a database that houses multidimensional data.
Relational databases represent data in two dimensions (think Excel or Google Sheets). OLAP, on the other hand, allows you to store data in multiple dimensions and promotes mobility within these dimensions.
Think of the OLAP cube as a Rubik’s cube where each block of the cube represents a data piece and each face of the cube represents the data dimension.
So, a marketing manager looking to understand how lead booking for the business takes place can run a query on EDW to see the:
Lead location (first dimension)
Lead booking data (second dimension)
Lead segmented by marketing channel (third dimension)
Time period (fourth dimension)
The biggest advantage with OLAP is that it allows end-users to filter and slice data to generate detailed reports. You can drill down into domain-specific information and run more complicated queries.
OLAP cubes can be hooked directly with an EDW or with specific data marts depending on the desired outcome. Most warehousing service providers, like Google BigQuery and Microsoft, offer OLAP as a service. You can customize your OLAP cubes based on your business needs.
Transforming Data Into Insights: The Next Steps
At the very start of the article, we explored how data analytics maturity is linked to EDWs. In fact, EDWs will drive demand for more machine learning and analytics solutions. A recent report by a research firm indicates that the global data warehousing market size is projected to breach the $50 billion mark by 2028.
With COVID-19 acting as a catalyst for digital transformation across industries, business users are increasingly looking to leverage their exploding pool of data to create a positive revenue impact. And understanding the chain of events that facilitate the flow of data is key to determining your data platform needs.
Building or deploying a data warehouse is a time and resource-intensive project, but the returns are well worth the cost. With the sheer number of options available, choosing the data warehouse solutions, ETL tools, and business intelligence tools best suited for your needs can be daunting.
Want to tap into your big data to generate meaningful business insights? Let’s talk.