SETFIT - Prompt-free Efficient Few Shot Learning | What is SetFit?
What is the the SetFit architecture and how does it outperform GPT-3 and other few shot large language models

Matt Payne
December 5, 2022

Let’s take a look at the most popular and easy to use deep learning based system called Neural Collaborative Filtering (NCF), published by National University of Singapore, Columbia University, Shandong University, and Texas A&M University in 2017. NCFs power comes from the non-linear nature of neural networks to learn a deeper understanding of the relationship between users and items, mixed with input from matrix factorization. This article will help you understand the NCF architecture as well as how you can implement NCF to provide buyers and customers with high ROI recommendations.
It might be helpful to have read our simple breakdown of general recommendation systems to help you understand some terms and ideas pertaining to why NCF implements different parts of the architecture.
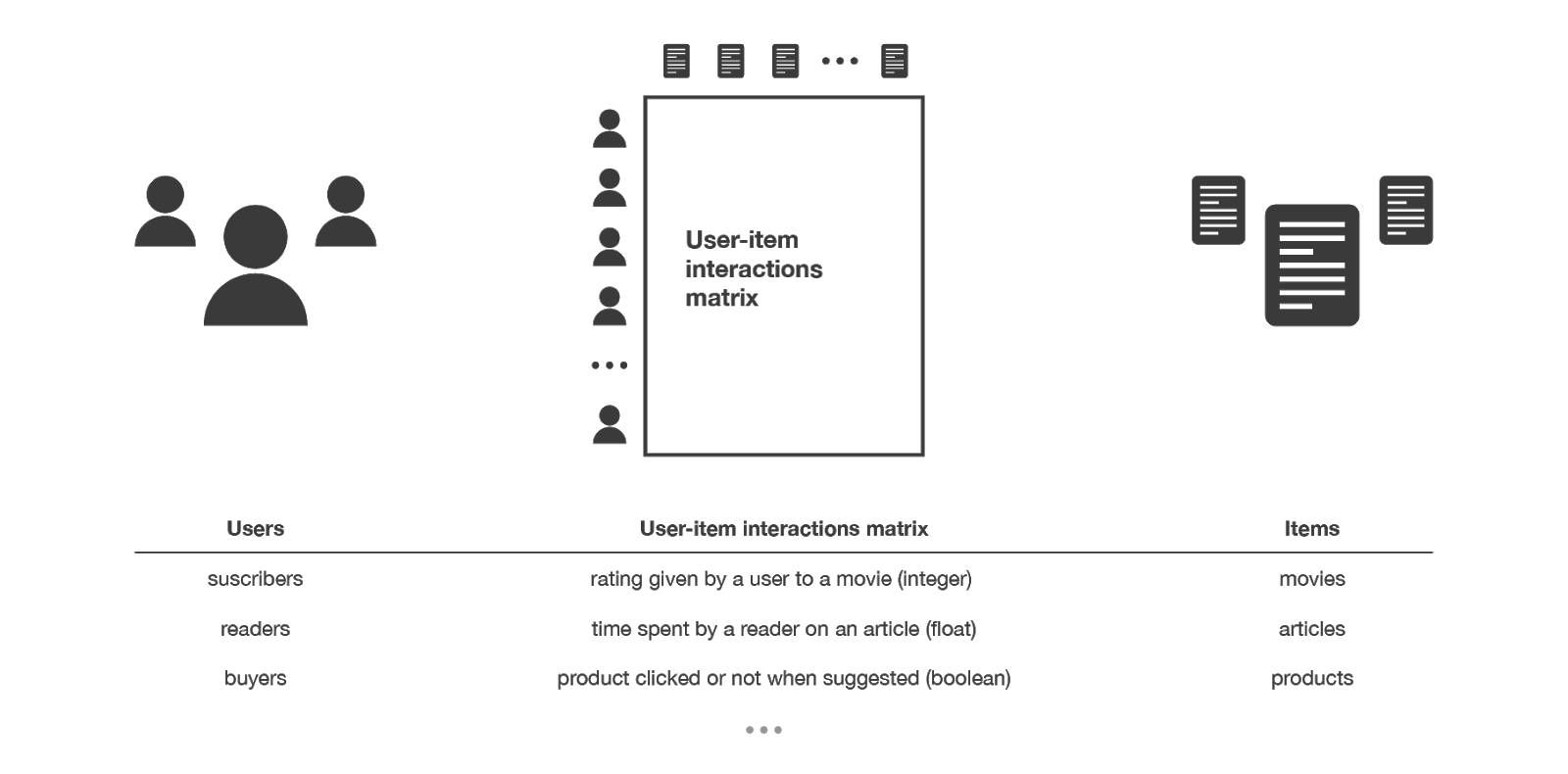
To understand the Neural Collaborative filtering model’s architecture we need to understand the input data required and how we engineer it for our use. The model takes in user ids and item ids corresponding to a target action. Many examples of NCF use users and movie ids, with the target being the rating the user gave the movie. These user and item fields must be converted to one hot encoded vectors, as these are not integer fields but identification numbers or user names.

Width.ai has used this same model for companies looking to recommend any user-item interaction such as a purchase or read article. Recommending products based on past purchases is a great way to use this model, and allows you to start making recommendations with a rather small input space.
Before we go any further into the model, it's important to understand the idea of implicit feedback and explicit feedback, and why we will be converting our data to implicit feedback.
Explicit feedback is data collected from users that is considered direct and matured, meaning the user had to perform an action for that data point to be created. Examples of this are all around, with things like retweeting on twitter, rating purchased goods 1-10 on a website, and clicking a link. The problem with this feedback data is these actions are rare, and the non action (not rating a video at all) are far more likely then the explicit feedback.
Implicit feedback however is the result of indirect data collection from user interactions, and is used as a proxy for a users preference. These are things like video watch time, searches you made in google, or views on a tweet. This data is far less sparse than explicit data and is used for deep learning architectures to recommend products in real time with quick updates.

One important note is that most of the data used for these systems has an explicit feedback target field, with things like movie rating, youtube subscription, or netflix subscription. We have to convert these data fields to implicit feedback points by reframing the problem. For example: Instead of trying to predict what a user would rate a movie (from 1-5) we will reframe it to predicting whether the user would rate the movie or not (1 or 0). The idea is this creates the highest likelihood of an interaction, and you can update your dataset to remove low ratings if wanted.
You might notice now if you’re following along is that you now have a dataset where your target variable is only positive output (a 1 instead of a zero). If a dataset contained only points where the user interacted with the item we now only have datapoints that are positive, no rows where the user did not interact with an item. We cannot train a machine learning model on only positive interactions, as the model will not learn the user-item relationship well. To fix this we have to add negative feedback targets to each user, to give the model a good blend of both. Many implementations recommend adding any random negative interactions to the user, arguing that even if a few are ones they’d actually want to interact with the chance of that being true is extremely low, and the benefit applied to the global loss outweighs the negatives. We’ve built a better function for applying negative sampling to our datasets that shows better results in the validation and testing datasets:
Now we’ve created our dataset, and converted it to an implicit dataset with one hot encoded vectors instead of ids. Before we pass data into the different parts of the model, we need to re-represent our data points in a format that helps the model understand the relationship between our vector data points. Embedding vectors are a representation of a lower dimensional space, used to capture relationships between vectors in higher dimensional space. We pass these high dimensional one hot encoded data fields into embedding layers that produce lower dimensional representations that help our model understand these sparse datapoints. We’ll use these embedding layers for both users and items and pass them into the model.

Although it's not really mentioned in the original paper, more recent NCF implementations use different embedding initializations and regularizations to improve performance. Glorot Uniform and L2 are both seen in Tensorflows implementation of NCF. Almost all newer implementations looking to model the same relations as NCF use these to improve early epoch training results.
Matrix Factorization has been used in older recommendation system implementations, including the Netflix Prize in 2009, but has been moved on from in recent years as a lone model for these systems. MF struggles to learn the relationship between users and items for sparse matrices and can result in high loss and unfit results on larger datasets. That being said it performs well as an input to neural network models and as a side model to feed learned relationships into a final output layer.

Matrix factorization of the embedding layers is the first operation we’ll perform, used to model the user-item interactions through a scalar product of the above latent vectors. Matrix factorization reduces the matrix of n-users and n-items into two sub-matrices to be multiplied together to form a final predicted matrix. Using a loss function we can compare these two matrices and focus on minimizing the loss between them. Mean squared error and root mean square error are the most common loss function used.

Matrix factorization of the embedding layers is the first operation we’ll perform, used to model the user-item interactions through a scalar product of the above latent vectors. Matrix factorization reduces the matrix of n-users and n-items into two sub-matrices to be multiplied together to form a final predicted matrix. Using a loss function we can compare these two matrices and focus on minimizing the loss between them. Mean squared error and root mean square error are the most common loss function used.
Diving into what happens here a little more, each embedding layer represents a matching user and item is represented in a latent space and represented by a latent vector. The more similar these latent vectors are, the more related the corresponding users’ preference. We can measure the similarity of any two matching latent vectors because we factorize the full matrix of users and items in the same space by using cosine-similarity or simple dot product. This all being said, the final prediction coming from matrix factorization is the inner dot product of the matching latent vectors. One point to note is that many people, including the original academic paper writers argue away from the dot product given limitations to fully model the interactions of one hot encoded users and items in the latent space.
Recommendation systems that use pretrained GMF layers to improve early training set results can be a great way to get low loss early and prevent overfitting and improve validation set hit rate. Width.ai has also experimented with Non-negative Matrix Factorization as a way to improve raw MF loss function results on sparse datasets.
.jpg)
The other “side” of NCF that operates alongside the MF implementation is a deep neural network model that takes the same one hot encoded vector to embedded vector inputs as the matrix factorization. Neural networks learn deep non linear relationships between users and items better than matrix factorization, and can scale to handle sparse inputs much better than matrix factorization with its dot product. Higher order inputs are passed into the multilayer perceptron models’ stacked hidden layers to learn these non-linear relationships between users and items. Most NCF implementations use 4-5 dense layers with under 100 neurons per layer, but many different sizes have been tested and productionized for use. For extremely sparse datasets we’ve used a 6 layer architecture with up to 256 neurons per layer, to allow the larger model to create more representations of the inputs. There is a point however, where it seems the ratio of items to users becomes way too large and requires a much deeper model, closer to DeepFM or FLEM.
All production level NCF implementations use ReLU for the activation layer in the hidden layers given its non-saturated nature, and with sigmoid being written off for its nature to stop learning as neuron values reach 0 or 1. LeakyReLU has become popular in other fields such as CNNs and GANs as an upgrade from ReLU, but no improvements have been seen in the realm of NCF with them.

To prevent overfitting on these datasets, especially ones with a low item to user ratio we use dropout layers and kernel regularization (mainly L2 as most modem DNNs do) throughout the model. Some models have opted to use both of these at every layer, although it's doubtful that's necessary given the struggle these models can already have to learn seriously sparse inputs.

The final proposed step in the Neural Collaborative Filtering algorithm is what they call the NeuCF layer. This final layer takes the concatenation of the output from the MLP and MF models as input into a Dense neural network layer. Combining these models together superimposes their desirable characteristics. The is the final layer that produces the prediction for a user and item pairing, determining if these two should result in being recommended. The result comes out as a percentage chance the model would predict a “1” for our target, or as we said before the chance the user would rate/like/subscribe to the item.

Due to the non-convex and noisy objective function of NeuMF, gradient based optimizations like SGD struggle to find a global minimum and settle for a poor local optimization. We can solve this with two different solutions, both of which have been outlined in the original paper and modern implementations.
Similar to the different implementations for optimizers as seen above, the loss function has become a talking point around what is best. Many implementations, including the original paper use log loss or also known as binary cross-entropy. This is the most used loss function by far, showing great results on datasets that use both a high number of users and high sparsity item datasets. Interestly enough, Tensorflow has opted for sigmoid cross entropy with mean reduction and passes the output from the concatenation function into NeuMF.
Interestingly enough, none of the standard implementations of NCF use any regularization in the final layer, but they do however use kernel initialization with Lecun Uniform, as seen in the original NeuCF code of the authors. The point where implementations diverge is the activation function, where the original authors use a sigmoid function but systems built by Microsoft and Tensorflow use none.
Evaluating NCF on test data can be a tricky task as we want to evaluate the system in a way that shows its results relative to a real world environment, instead of loss or accuracy based metrics. The NCF academic paper lays out results calculated from Top-k Hit Rate and Normalized Discounted Cumulative Gain with a ranked list of 10 items being the cutoff. Hit rate is used to measure if a specific positive interacted test item appears in the top 10 out of 100 items, with the other 99 items being randomly sampled. NDCG is similar but uses a focus on how high the item is in the list by assigning higher scores to hits near the top of the list.
Evaluation datasets are set up using leave-one-out evaluation, which is widely used in recommendation systems to evaluate recent interactions from users. Leave one out will produce an evaluation dataset with just positive interactions, so random samples have to be pulled from the main dataset. Evaluation should be run often, as it can be difficult to predict the evaluation results based solely on the training results, given our metrics are quite different for both.

Amazon's secret weapon is its personalized recommendations used to increase customer LTV and email marketing ROI. Huge ecommerce companies have made it clear that they plan on using recommendation systems at all stages of their sales funnel to put products in front of potential customers that they want to buy. If you’re an ecommerce store looking to compete moving forward or have a subscription product and want to increase user engagement, personalized recommendations have been proven to be a requirement in 2021.
With the state of modern recommendation systems you can avoid many of the problems endured with past systems like the cold start problem, by implementing item based recommendations to build deep sales data and moving towards personalized recommendations for a user. Amazon published this paper explaining how they start with item recommendations and use them for on-site similar products and bundles. Data collected with these systems plus real sales data allows them to move towards personalized email marketing campaigns to retarget existing customers. This should be no surprise, as this combination of the best digital channel for ROI& powerful recommendations is moving ecommerce giants along.

But let's not forget, recommendations aren’t just for ecommerce and retail. Subscription based businesses like Netflix have been at the forefront of modern recommendation systems as early as 2006. Models like neural collaborative filtering help subscription products present customers with better product services, increasing user engagement. As we said before, Netflix has stated that 80% of stream time is achieved through recommended movies and shows, clearly improving retention rate and keeping users engaged.
Neural Collaborative Filtering is a great way for small businesses to get involved in the growing push for personalized recommendations in sales and marketing. The model requires very little data in terms of features (only 2) and can be adjusted and augmented to fit different recommendation use cases depending on where in the sales cycle the data comes from. Simple product recommendations based on purchasing history can be easily done with this model and can be used in many email upsell campaigns to past customers.
Interested in learning more about how recommendation systems could be implemented in your business? Width.ai has built powerful recommendation systems for huge userbases, and understands how your data can become valuable personalized recommendations quickly. Let's talk today!
