Let's take a look at how you can use spaCy, a state of the art natural language processing tool, to build custom software tools for your business that increase ROI and give you data insights your competitors wish they had.
What is NLP?
Natural language processing is the study of our natural language through speech or text, and how it can be manipulated or understood by software and algorithms. Studying NLP has been around for a long time, more than 50 years, and has gained interest from deep learning and data science developers with how we can build models to produce, manipulate and understand text.
While NLP picked up with a focus on using statistics and classical linguistics models to process our language, we have turned a corner and now use deep learning neural networks as the focus point for NLP based systems. Many large research groups have focused on building large models already trained on billions of words (like GPT-3), while many other architectures come with a few smaller pre-trained models but allow you to easily and efficiently train the model on whatever you want to use it for (Bert/spaCy/Tensorflow). One of the most important parts of NLP is processing and deriving insights from unstructured text data for other ML use cases, a task that can be daunting without NLP.
What is SpaCy?
import spacy and a code example
SpaCy is an open source library for enterprise grade NLP in python. SpaCy stands out amongst some of its competitors (NLTK) because of its cutting edge abilities and is designed specifically for production use. This tool is perfect for answering questions based on text like - “What companies are mentioned in this article?”, “which paragraphs are similar to each other?”, “Where do I add my credit card?” as well as perform tasks like text classification. SpaCy comes with many pre-trained models in all different languages that are amazing out of the box, but also allows you to train custom models on your own data to optimize for your specific use case.
Processing pipeline in spaCy
SpaCy allows you to use a processing pipeline to move from raw text to the final “Doc”, which lets you add different pipeline components to your NLP library and act on your input. Things like a tokenizer, tagger and parser act on the Doc. You can also add things like statistical models and pre-trained weights for different tasks, or use built-in custom components.
With the wide range of capabilities of spaCy you can imagine there are a ton of business oriented components that allow you to build simple or complex software tools that can help you increase product ROI, assist you with customer service, or reduce your manual workflow - saving you a ton of money. Let’s first take a look at a few important capabilities of spaCy in a little more detail, then dive into some business tools to build.
Features of spaCy For Natural Language Processing:
Part-of-speech Tagging For Predictions:
A combination of the transformer based pipelines and a statistical NLP model can be used to make predictions about what part of speech a word or sentence is part of using part of speech tagging. For instance understanding words like “looking” or “buying” are verbs, while “apple” is a noun. This feature also uses context clues in the text to understand words and what the context is. For example words following “the” are most likely to be a noun.
Named Entity Recognition:
Named Entity Recognition
Named entity recognition is used to recognize various types of real world objects in paragraphs or documents, such as personal names, companies, countries, and types of items. The method looks to classify named entities in unstructured text into said categories. Many models are trained on billions of lines of text and usually require a little more tuning for your use case, but do achieve over 90% accuracy on most test datasets.
Word Vectors and Understanding Similarity:
Taking a look at word vectors, or the multi-dimensional representations of words, we can compare these vectors to understand how closely related two words are in their meaning and usage. You might have already heard of this concept of word vectors, as they are popularized by the neural network based algorithm word2vec. Graphically these vectors look similar to anything you’ve seen vectorized, like images. You’ll see that the higher dimensional representations of similar words (for example: queen, princess, lady) will actually cluster together and allow you to see that your graphical space understands which words are similar. We’ll see this concept used quite a bit in our business projects with things like recommendation systems or automation tools.
Let’s dive deeper into talking about similarities with words and representations, as this will be important to understand. The concept of similarity when referring to words is extremely complicated, for a bunch of reasons. Words can be related to each other in a lot of different ways, so using a simple similarity score can be difficult to apply to generalized tools. One person might consider the word “nurse” similar to “dentist” as they are both referring to workers in the medical field. On the other hand one might consider them not similar in an application
Word similarity mapping
given they are considered different professions. Part of this difficulty to generalize a similarity matrix model can be reduced with tuning specifically for the application as well as affecting the way words are evaluated. Instead of evaluating based on the average of the vectors you can include the order of the words to enhance the understanding of meaning.
Transformer Embeddings:
SpaCy lets you use a bunch of transfer and multi task learning workflows from other natural language processing libraries like BERT to improve accuracy for your pipeline. Using spaCy these techniques let you import learned knowledge from other tools directly into your pipeline, so your custom model can generalize better.
Rule-based Matching:
A look at using the Matcher class in spaCy
spaCy has a tool called the Matcher, that allows you to implement rule based matching on tokens and dig deeper into the relationships between tokens by looking at things like the surrounding tokens or plural forms of words. We can also create patterns that let you build rules that have multiple flags like, 1. A token must be all lowercase 2. A token whose flag IS_PUNCT is True 3. The lowercase form must match the work “hello”. The Matcher is very useful for custom models that are looking to parse out a lot of what is seen in the unstructured text.
Inflection Morphology In spaCy:
Inflectional morphology is the process of adding morphological features to a lemma to create a surface for a word, for instance changing read to reading. The action does not change the original words part-of-speech, but does linguistically allow us to use the word in a different meaning. We will use the reverse of this process to understand context of objects (words), and useful things like mood, tense, and verb form.
Rule-Based Morphology:
This spaCy feature allows us to assign any morphological features to lemma through a rule based approach, similar to what we talked about earlier with rule-based matching. Using the token text and part-of-speech tags, we can add or remove morphological features.
What Can We Build to Increase Business ROI?:
Lets take a look at some of the state of the art tools people have built using specifically spaCy, as well as some general tools we can build that optimize and perform better with spaCy as the main component, instead of other natural language processing models.
NLP Chatbots:
One of the most widely known use cases for NLP systems is chatbots. Chatbot use across industries has accelerated quite a bit in the past year due to covid. The future growth of the chatbot industry is exponential, with the sector expected to be valued at $9.4 billion by 2024, up quite a bit from $2.6 billion this year.
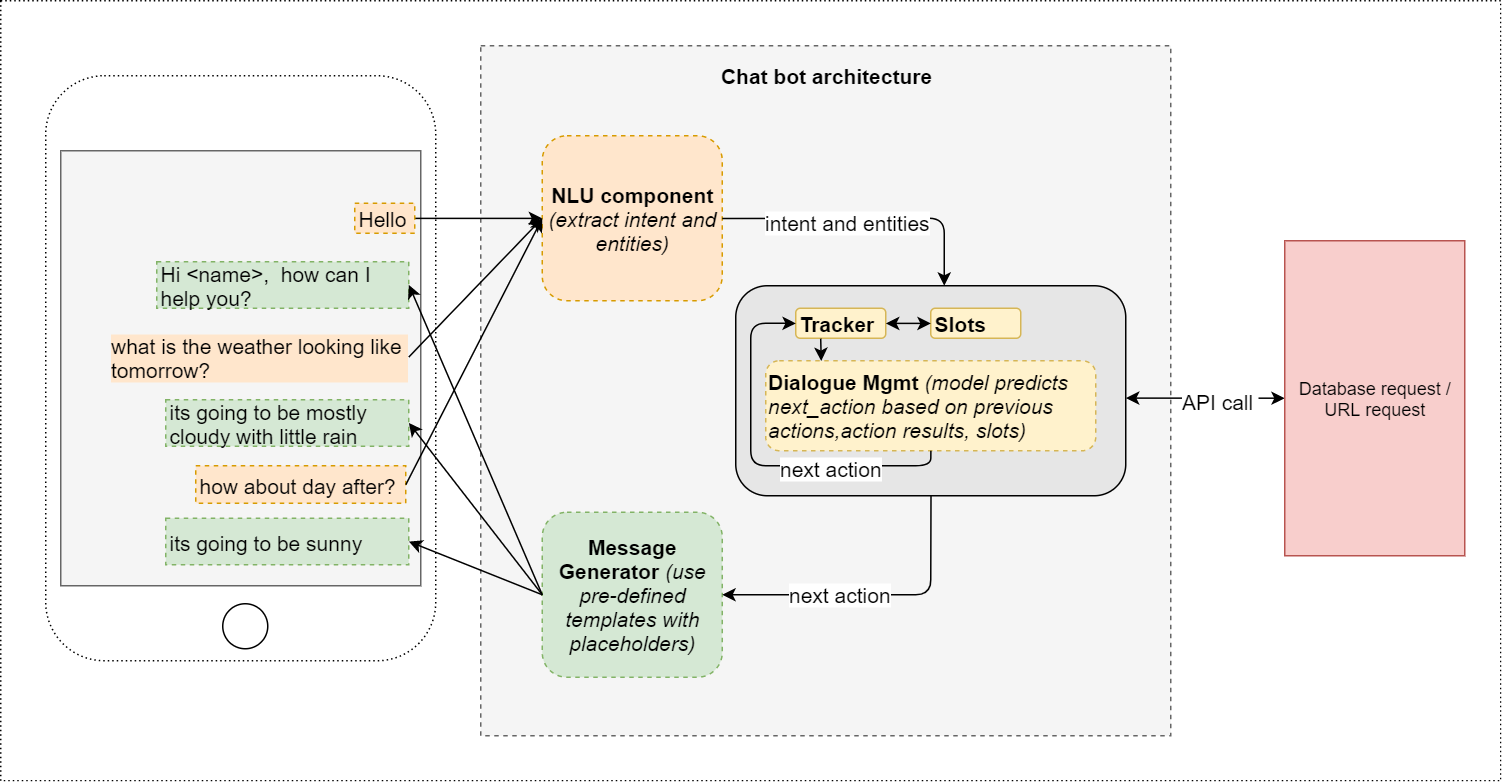
chatbot architecture
Why Chatbots?:
Industrial strength chatbots are great at managing customer relations, with tools like customer support chat boxes on websites or facebook, to automated call centers that try to solve problems without needing human interaction. However, in recent years chatbots have started to be used for a different use case, this one directly increasing ROI and conversion rates for companies selling things online and offline. We’ll look at how to accomplish both of these, but let's first look at a spaCy tool that gets us there.
ChatterBot:
ChatterBot is a spaCy based conversational dialog system built using python. This NLP library allows us to build and train chatbots easily with its conversation based training style. Every time we put in a statement the library saves the text, as well as the response it outputs as training. As we continue to add more input statements to the model the accuracy of the responses increases, relative to the increase in statement objects.
ChatterBot is language independent, meaning it is incredibly easy to train it to speak any language. An untrained instance of ChatterBot starts off with essentially no knowledge of how to respond to questions or what to do to communicate. This makes Chatterbot very easy for us to train for our specific business use case, but difficult to generalize if we were looking for that.
Customer Service With NLP Chatbots:
Building customer support tools with chatbots is one of the fastest ways to reach a level of automation in your business, for anything from online retailers to SaaS platforms. These chatbots are trained to answer questions related to your products or platform like “how do I add more users to my plan?” or “how many emails per month comes with the silver tier?”. They can be trained on your FAQs or simply your most asked questions, and answer all different formats of questions and in all different tones of voice. Many newer models can suggest relevant answers to questions before the customer finishes, as well as frequently asked questions that are close to their question (going on the silver tier question above, the bot could also answer - “Silver tier allows you to have 4 users to send those emails”).
These customer service chatbots help reduce workload of customer service reps and info@ email response teams that deal with countless inquiries per day. This lets you keep less people going at the same time saving you time and resources. Sales people can actually get back to generating you leads instead of having to help with customer support off and on, which you see at small startups. Currently bots are very good at answering simple questions and augmenting these interactions to keep the customer moving through to the answer without human input. Companies are seeing the benefits of using these bots to reduce workload, with Amazon implementing a huge customer service chatbot system in early 2020.
Increased ROI With Chatbots:
Chatbots are being used more and more on the offense in many large companies, with a clear way to increase ROI and conversions with new or existing customers. Companies such as IKEA are gathering customer feedback automatically using these bots, by asking simple yet targeted questions about products and service. This lets you optimize parts of your sales funnel or product that your customers are looking for, without sending spammy emails or asking them to go to another link and fill out a form (which they won’t do). These chatbots are simple and elegant and get filled out much more often than the above.
Chatbots are great at assisting confused (and likely to leave) customers through a buying process or funnel. They can offer quick assistance for simple questions that are asked frequently OR can offer to answer questions the user might have strictly based on how they interact with the page. Tools like Heatrr.ai pair well with a chatbot and give you behavioral analytics into what users do on a page like a long form sales letter and can help the chatbot ask questions to keep the user moving through.
Tip: Named entity recognition can be useful here, as it allows us to look for specific product names or SKUs that the user is struggling with.
Sentiment Analysis Tools With spaCy:
A look at sentiment for tweets with grand canyon in the tweet
Sentiment analysis using spaCy is a great way to collect insight rich information about your products or brand from a ton of different sources like emails, social media, and product reviews. The information you extract from raw text for sentiment analysis can be helpful in predicting customer trends in the future, as well as make adjustments to your brand right now based on how customers feel about you and your products. Huge companies like Intel, Twitter and IBM are using sentiment analysis right now to analyze huge chunks of data.
Using spaCy’s large english language model we can train a model to analyze social media posts or tweets to understand what people are saying about our product, or even better our competitors and see what they don’t like about it. SpaCy makes it easy to build and train this model with its pipeline design, as well as the fact that we just have to tune the model for our company specifics. From the example above of looking at our competition, not only can we figure out if they’re unhappy with what they got from the competitor (and maybe we offer them a discount if they try our product), but we can extract and analyze certain words that we might want to think about in regards to ours. If we use rule-based matching to extract words like “cheap” “low quality” “fell apart” we can evaluate the business decisions we are making and make improvements.
Improve down-time reactions with Sentiment Analysis:
SpaCy can allow us to tune our model to look for tweets or posts about our system or website, and respond to outages faster. Let's say we have a model looking for negative tweets that include our support account, we can find website outages faster and make fixes for our customers. Imagine how nice it would be to get one of these alerts the second your users are frustrated “system glitched and it used 2 email credits instead of one, WTF @companysupport. Disappointing - might have to make the switch!”. Not only would you be able to manually respond to this user and fix the error, but if you have also implemented a chatbot you could respond with that as well.
Generate Extremely Warm Leads:
Finding negative posts from your competitors customers to improve your product quality isn’t the only way you can use this valuable spaCy model. Building a database of people who are unsatisfied with a competitor is a great way to find super warm leads for your product. These people are already using a product they need, and are unhappy with their current situation. You can offer them a small discount and high quality customer service to join your platform, and these potential customers convert at a very high rate. Adding in certain rule-based matches such as “done with them” or “new product” can help you find even hotter leads that could be some of the easiest conversions you’ve ever had.
Named Entity Recognition Based Tools With SpaCy:
Named entity recognition (NER) is one of the most interesting out of the box tools spaCy provides, the ability to recognize things like people, companies, prices, and products in text can be quite useful. SpaCy based tools like NeuroNER allow us to build very powerful systems using spaCy and neural networks.
Extracting Data For CMS Automatically:
The capabilities of spaCy to conduct NER are pretty good right out of the box, but with tuning on data just for your business use it can become incredibly accurate. Plenty of work has been done to extract entity objects from more official text like news articles or blog posts, but informal text like emails or texts can be a little different. These types of text don’t follow grammatical rules and can have lots of errors, as well as the fact that these aren't typically written for a large generalized audience like new articles.
A look at NER finding names in an email
Building a tool that automatically extracts things like email address, phone number, name, company, and prices from emails can allow us to automatically add new leads or prospects to our CMS systems and help us automate part of our sales flow that might otherwise be forgotten about. We find many information points that don’t automatically get saved in CMS systems like discussed prices or product quantity. Deeper text analysis will help us add a short one liner that gives us context for what the emails are about. Trained on pretty basic email datasets with the addition of a dictionary in the training (To help generalize with more words) these models have seen over 90.7% accuracy that lets you automate this part of your lead generation.
Web Scraping With NER in spaCy:
Building datasets based on competitors for research or building machine learning models can be a very long process. Digging through product pages, recording prices, SKUs, personal names, and so much more. You can also scrape this data automatically, but it won’t be labeled and you’ll end up grabbing everything your web scraper sees and you'll have to label things later.
Using NER we can decide on the named entities we care about (or labels) and scrape just the important stuff. If we train our spaCy model on information relevant to what we want we can automatically scrape everything we need, with the entities as the labels. This makes market research or model training extremely fast and lets us continue to grab data, which is almost always valuable when it's niched down like this.
What's awesome about spaCy is we can create our own custom entity labels when we tune an existing model's nlp vocab. We can create that SKU label when we train and now our web scraper will look for SKUs and understand what they look like. This can be very useful when we’re scraping very oddball things, for example if we wanted to find the name of sports card sets (they use keys like N28 to describe the year and company) we can do that, as the plain model wouldn’t know what those mean.
Interested in seeing what NLP models can do for your startup or small business? Want to start collecting insights that gives you ROI your competition would beg to have? Let's talk about how we can use Ai and NLP to increase conversions and find potential high value customers hiding in plain site.