How to Deploy Custom WordPress Chatbots for Happier Customers
Find out how AI-powered chatbots can make WordPress even better for your business. We’ll show you how custom chatbots compare to Wordpress’s plugins.

Matt Payne
March 5, 2024
Beam search is an algorithm used in many NLP and speech recognition models as a final decision making layer to choose the best output given target variables like maximum probability or next output character. First used for speech recognition in 1976, beam search is used often in models that have encoders and decoders with LSTM or Gated Recurrent Unit modules built in. To understand where this algorithm is used a little more let's take a look at how NLP models generate output, to see where Beam search comes into play.
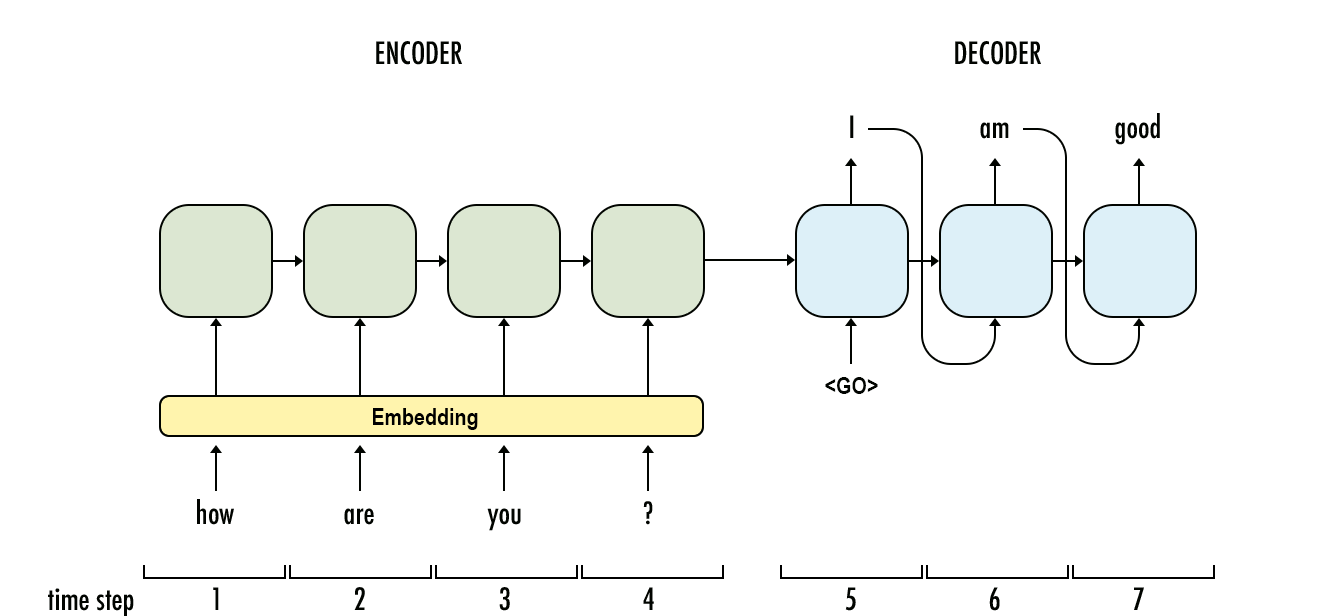
Sequence to sequence is a deep learning based NLP model used for machine translation and speech recognition that predicts the probability of the next token in a sequence of words. In speech recognition, the input audio sequence would be encoded with a recurrent neural network and feed into a decoder for prediction or speech classification using different ending layers. For this example, we're going to look at text language translation, where the decoder produces a new sentence in a new language. The encoded text from the original language sentence is fed into the decoder along with what we call a "Start" token to seed this runs output.
This new representation is passed through an output layer, which contains a softmax function to output a probability of the likelihood of each word in the new sentence appearing, as well as the word appearing in that position in the output sequence.
Of course, the goal of this model in our mind is a correctly translated final sentence. How does the model reach that final score and sentence that it believes to be the most accurate translated sequence? Given the number of combinations of probabilities of sequence positioning as well as probabilities of which word to place in a given position, there has to be an algorithm to decide, right?

Greedy search will simply take the highest probability word at each position in the sequence and predict that in the output sequence. Choosing just one candidate at a step might be optimal at the current spot in the sequence, but as we move through the rest of the full sentence, it might turn out to be worse than we thought, given we couldn't see later predicted positions. As we'll see later and you can probably predict, as our outputs become longer the greedy search algorithm begins to struggle.
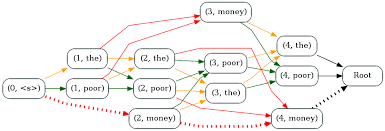
The beam search algorithm selects multiple tokens for a position in a given sequence based on conditional probability. The algorithm can take any number of N best alternatives through a hyperparameter know as Beam width. In greedy search we simply took the best word for each position in the sequence, where here we broaden our search or "width" to include other words that might fit better.
Greedy search looks at each position in the output sequence in isolation. A word is decided based on highest probability and we continue moving down the rest of the sentence, not going back to earlier ones. With Beam search, we also take the N best output sequences and look at the current preceding words and the probabilities compared to the current position we are decoding in the sequence. Let's walk through an example to see the steps we must take to use beam search effectively.

Lets set our beam width to 3 and grab the top three predicted words at each position in a given sequence. The encoded audio sequence is passed to a decoder, where a softmax function is applied to all the words in a set vocabulary (would be previously defined no matter if we're working with audio sequencing or text translation).
Lets set our beam width to 3 and grab the top three predicted words at each position in a given sequence. The encoded audio sequence is passed to a decoder, where a softmax function is applied to all the words in a set vocabulary (would be previously defined no matter if we're working with audio sequencing or text translation).

For the second word in a sequence we pass the first three selected words as input into the second position. As we did before, we apply the same softmax output layer function to the set vocabulary find the next 3 words we could use for the second position. While this happens, we use conditional probability to decide on the best combination of first position words and second position words. We run these 3 input words against all words in the vocabulary to find the best 3 combinations and will pass them to the next layer as input again. Words from the first position can get dropped moving forward if another input token has a higher probability with two different sequences. For instance, if "I will" and "I am" were higher than any combination with "Us" we can drop the "Us" token and continue with our new top three sequences. We repeat this process until we reach an END token and have now generated 3 different sequences.
We now have 3 different text translations or audio sequence results that we still have to decide between. These output sequences can be different in length and total tokens, which can create nice variation in our results. We simply pick the decoder output with the highest probability at the end.

Beam search doesn't have to be used for sequence based models where we use encoders and decoders to build large text and audio systems. Beam search can be broken down to a graph search where the points are possible are tokens in the input and we order all partial solutions according to some optimization function. Beam search builds its search tree using breadth-first search where the lower leaves of any given leaf are all possible states past the current leaf. We can use the beam width control how many leaves we can remove from the entire tree, where the higher a beam width the more leaves we leave and fewer are pruned. We can then use this as a breath-first search that uses the beam width as a memory control, in situations we want to account for run-time and tree size.
In terms of text sequence analysis like we saw above, a lower beam width will produce worse translations as the width moves towards 1 (which is the exact same as a Greedy Search), but becomes faster and more efficient. Many implementations start with a lower number for the beam width and progressively move it up as output results keep improving.
