Deep learning has achieved miraculous results for some years now. It can match human-level vision and speech capabilities, generate realistic art, and beat top players in games. But a major obstacle to using machine learning in a real production environment is the training or fine-tuning process. Gathering data, labeling classes in images, training models, and managing data variance coverage can be extremely expensive and time intensive and pretty low ROI when looking to get something out as quickly as possible.
This is where zero-shot learning methods can be immensely useful to businesses looking to quickly leverage computer vision models. Zero-shot methods enable engineers to use a model out-of-the-box with very little data and manual resources required for building the datasets.
How is this possible? In this article, you'll learn about zero-shot object detection, a capability that is potentially useful to a wide swath of industries.
What Is Zero-Shot Object Detection?
Given an image it hasn't seen already, normal object detection (OD) locates and labels all the objects that it's trained to identify. Importantly, the labels it assigns are always from a fixed set. That's why the task is sometimes called "closed vocabulary" detection. Because all the labels are present in the training data, they're called "seen" labels or classes.
In contrast, zero-shot object detection (ZSOD) attempts to identify objects with labels it's never seen before while training. It does this by figuring out the semantic distances of the unseen labels from the seen classes and projecting those distances on the visual concepts it's learned.
One of the main benefits of ZSOD is that it allows you to start using object detection with a much smaller or no dataset.
A Quick Demo
A demo of zero-shot object detection using a smartphone in a retail setting is shown below (the odd labels are because the unseen labels supplied are from a non-retail dataset).
More on Unseen Labels
Where do unseen labels come from? The set of unseen classes depends on the problem being solved and must be supplied to ZSOD along with the image being processed. For every image, a different set of unseen categories, possibly context-dependent, can be supplied.
ZSOD by itself is not a generative task that can create new labels on its own. Instead, it selects the most relevant label from a set it's given. Such a set is often generated using other natural language processing tasks like image captioning.
Another aspect to note is that, traditionally, labels are nouns or short noun phrases (like "wine bottle" or "blinder for horses"). But modern ZSOD supports long, natural language descriptions with any number of words, phrases, sentences, or even paragraphs. For these reasons, modern ZSOD is a type of "open vocabulary" detection.
ZSOD's use of unseen labels may seem a little non-intuitive. Later in this article, we'll demonstrate its usefulness with practical examples.
What Are the Benefits of Modern Zero-Shot Detection?
Here are some benefits of modern zero-shot detection (ZSD) compared to traditional object detection:
Eliminate the training process: Traditional OD can only identify the object classes it's trained on. If it sees unseen objects, it can neither detect nor identify them. Upgrading such systems requires hiring machine learning experts. In contrast, modern ZSOD can handle any new category it runs into, even categories that don't yet exist.
Use natural language to interact: Traditional OD often uses short, precise nouns or noun phrases as labels. It isn't capable of recognizing an equivalent label that is longer or descriptive. Many users find such failures frustrating. But modern ZSOD takes advantage of advances in language models to understand or generate long textual descriptions in natural language. You can basically speak to ZSOD or chat with it naturally, even use vague or fuzzy descriptions, and it'll still detect and identify whatever you want.
Future-proof use: As large language models like GPT3 and ChatGPT keep getting more intelligent and capable, ZSOD systems that use them also benefit.
Seriously cost effective: Building very niched datasets can be extremely expensive as the data often has to be manually collected and annotated. Traditional object detection in a retail setting requires 5,000+ examples per class to reach production accuracy. Some object recognition use cases require the annotator to have in-domain knowledge about the industry which usually means they’re more expensive per image.
Related Machine Learning Approaches
If you're familiar with machine learning, you're probably thinking right now about other tasks that seem confusingly similar to ZSOD. We clarify their differences below:
Image captioning: Unlike ZSOD which picks a label from a set, image captioning can generate textual descriptions for an image. Image captioning can generate a genuinely open vocabulary, especially when used with large language models. These generated descriptions can become unseen labels for ZSOD on more images.
Sequence-to-sequence paraphrasing: Given a text description, paraphrasing can generate additional text descriptions that have the same meaning.
Semantic similarity using text embeddings: Given a text description, it can find the seen labels that are semantically similar.
These tasks are not mutually exclusive with each other or ZSOD. They can be combined for your particular use case and desired goals and many can be used in a zero-shot setting as well.
In the next section, we take the retail industry as an example to explore how ZSOD can be used in practice.
How Is Zero-Shot Object Detection Useful?
Let's see some practical applications of zero-shot object detection in different industries. You'll also understand how unseen labels work in practice. While imagery often comes from customers, employees, or monitoring systems, unseen labels can come from various internal and external systems, and that is the key to exploiting ZSOD for novel intelligent capabilities.
Retail and Product Recognition
Many retail and product recognition workflows can benefit from zero-shot object detection by potentially saving time, reducing costs, or improving sales.
In-store inventory management keeps track of all the items that are kept on display to be sold. It tracks their current state (displayed, sold, spoiled, stolen, and so on), their current stock, their locations in the store, their prices, any offers on them, and other details.
ZSOD can help retailers in several ways. For most of these use cases, the images come from customers or employees while unseen labels can be sourced from the inventory database, public retail datasets, or product catalogs:
Manage variety: Store items come in a wide variety of sizes, shapes, and packaging. Greater variety requires more employees and more time to manage. For example, small items can't be barcoded or counted easily during restocking, annual counting, or cycle counting. ZSOD can help out by identifying and counting even the items it has never seen before without any kind of retraining.
Quickly build a product image database from scratch: A product image database enables a retailer to 1) offer an e-commerce website for online sales 2) use automation for tasks like product counting 3) offer visual search via mobile apps or in-store kiosks to help customers. ZSOD is the quickest, easiest way to build a product image database from scratch. Just take photos using your smartphone and you're done. Even small, mom-and-pop convenience stores can benefit by reducing the time spent.
Support planogram preparation and compliance: Planograms are guidelines for positioning products based on customer psychology. Planogram rules are often expressed in terms of sizes, colors, categories, and so on. For example, don't keep mismatched colors together or don't separate categories that are frequently bought together. Manually labeling every product with sizes and colors is impractical. However, ZSOD can identify them dynamically using unseen descriptions derived from the rules, like "tall green bottles" or "cartons with cartoon characters for children."
ZSOD can also enable personalized recommendations for customers. For example, a customer can ask the system to alert them when a product of interest is in stock using descriptive (unseen) queries like "a rose-colored dress" rather than specifying particular brands and possibly missing out on a great buy.
Factory floors and assembly lines are busy places where floor managers and technicians may need to track parts, spares, tools, and other objects in real time. It's time-consuming for employees to enter these details manually into a tracking system.
Instead, they can use ZSOD to snap photos regularly, visually detect objects, identify them, and enter their state or count in the system. The unseen labels can come from procurement systems or industry-specific catalogs.
How Is Modern Zero-Shot Object Detection Implemented?
Text is an integral aspect of ZSOD in the form of unseen labels. For a long time, a limited set of concise labels was the norm. But many use cases can benefit by using longer, descriptive, open-vocabulary natural language labels. That's possible now, thanks to large language models and vision-language models.
Vision-language models can jointly learn visual and language features using expressive and efficient architectures like transformers. Newer models for computer vision tasks have also started using them but convolutional neural networks remain quite popular.
Zero-Shot Object Detection Using RegionCLIP
In these sections, we'll analyze Microsoft's RegionCLIP model in depth to understand how to detect object classes in a zero-shot setting using vision-language models.
CLIP stands for contrastive language-image pretraining. It's a pioneering vision-language model from OpenAI that has learned to reason about visual concepts in images and their natural language text descriptions from 400 million images and captions. When given an image, it selects the best text description for it; when given a text description, it selects the most relevant image that matches. Essentially, CLIP can do zero-shot recognition.
It uses contrastive learning to judge the closeness of any two data samples or find the nearest match. Each sample is an image-caption pair. The benefit of contrastive learning is that assessing the closeness of samples is much more efficient than learning to predict or generate a result. And by using readily available image-caption pairs from the web, it can scale up in a self-supervised manner without any manual annotations.
Why CLIP Can't Detect Objects
Unfortunately, CLIP is optimized for full-image classification. A naive approach to reuse it for object detection is using a normal detector like a region proposal network (RPN) to get object proposals, crop them as separate images, and submit them with a set of text labels that CLIP can identify. This is a similar architecture to what we use for our product recognition pipeline at a SKU level.
But this exact approach shows poor accuracy. One reason may be that a caption is for the full image and may not contain object-level descriptions. Another reason may be that when objects are cropped, it doesn't have the surrounding visual space to identify them better.
Overview of RegionCLIP's Approach | The Better Approach
To overcome these problems while retaining CLIP's expressiveness, RegionCLIP reuses CLIP's models with some simple enhancements. Its simplicity makes it a useful template that other vision-language models can follow for zero-shot object detection.
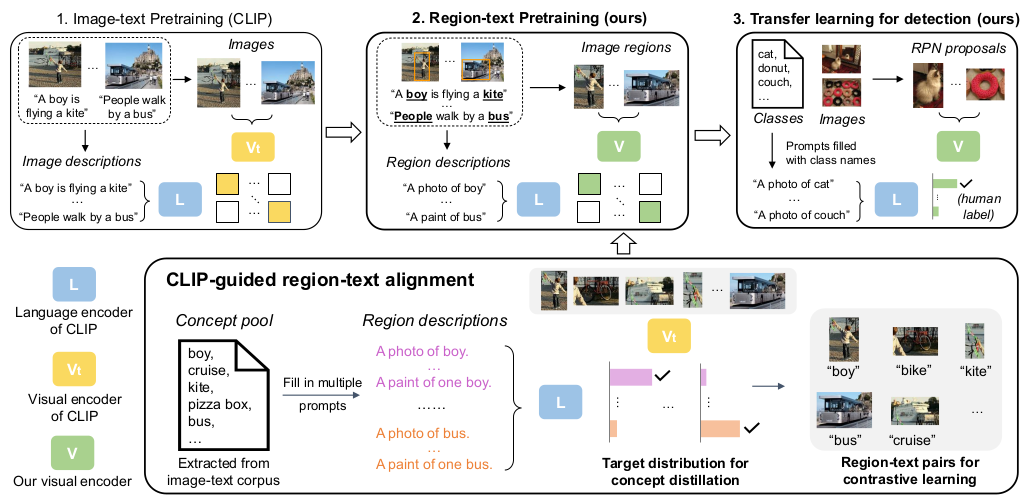
In a nutshell, RegionCLIP is CLIP but for the regions of an image. While CLIP operates on the full image, RegionCLIP learns to reason about visual concepts and text descriptions of regions. It does so through three ideas:
Generate a dataset of region-description pairs from any existing image caption dataset without any manual labeling. Since the web will never run short of photos and captions, RegionCLIP can scale up its knowledge forever with minimal effort.
Use a pre-trained CLIP model as a teacher to learn the visual representation of regions.
Transfer its region-encoding capabilities to a zero-shot object detector.
In the next section, we delve into each of these ideas. But first, a note on RegionCLIP's architecture.
RegionCLIP Architecture
RegionCLIP builds on CLIP's architecture. To keep its architecture flexible, it decouples the three visual tasks of region localization, region representation, and object recognition:
For region localization and recognition, it just leverages an off-the-shelf RPN detector like faster RCNN with a ResNet50 backbone.
For region representation, this ResNet50 backbone acts as a visual encoder and is just CLIP's pre-trained ResNet50 model. Given an image region, it can produce an embedding that represents the region in a visual semantic space.
The text encoder that produces semantic embeddings for region descriptions is just CLIP's pre-trained transformer encoder.
We'll now dig into the details of the three main ideas of RegionCLIP.
Generate Region-Text Datasets Automatically
Generate region descriptions from image captions (Zhong et al.)
Plenty of image-caption datasets are out there on the web. Unfortunately, most of these captions tend to describe the overall scene and not the objects therein. So where does one get region-description datasets?
RegionCLIP seeks to generate them from existing datasets as follows:
For each image-caption pair, run a scene graph language parser on the caption to obtain a set of object concepts. In the illustration above, boy, kite, people, and bus are the object concepts.
Insert these concepts in a set of template phrases to get natural language descriptions. For example, for "bus," it generates "a photo of a bus," "a paint of a bus," and so on.
You now have an image and multiple descriptions containing concepts but you don't have the object regions yet.
So run a pre-trained object detector like faster RCNN to detect all the objects in the image.
Now, you have a set of object regions and descriptions.
Use the visual encoder to get an embedding for each object region. Extract it from the last ROIAlign pooling layer.
Use the text encoder to get text embeddings for all the descriptions.
Do this for all images in the dataset.
After this stage, you'll have:
Visual embedding vectors for all the proposed object regions
Text embedding vectors for all the descriptions containing object concepts
Text embedding vectors for all the object concepts
Use CLIP to Teach Region Representation
CLIP-guided pre-training (Zhong et al.)
The visual encoder must be taught to select the best description for each region. This is also called aligning the text descriptions with object regions.
For this, RegionCLIP uses knowledge distillation with CLIP's visual encoder as the teacher and its visual encoder as the student. In knowledge distillation, a student model learns to reproduce the teacher model's results. Remember that the student encoder has already been initialized with CLIP's own encoder weights. Now we have to refine it to align image regions with the best text description.
First, pair all the candidate region embeddings with all the description embeddings. This is our training dataset.
The loss function to be minimized has three components:
Contrastive loss: It accounts for distances between every two samples. The goal is to minimize distances between similar samples and maximize the distance between dissimilar ones.
Distillation loss: For each region, both the CLIP teacher and the RegionCLIP student estimate probabilities for each of the descriptions. Distillation loss measures the deviation of the student's probabilities from the teacher's. Since both are probability distributions, their distance is calculated as a Kullback-Leibler divergence.
Image-level loss: It makes use of the image-caption pairs too to ensure that the description for the full image is close to its original caption. This is also a contrastive loss. For the negative samples, just combine images with the captions of other images.
The result of this training is a pre-trained visual encoder that can do region representation and align image regions with text descriptions.
Transfer Learning for Object Detection With RegionCLIP
Transfer learning for zero-shot object detection task (Zhong et al.)
The final stage is transferring the pre-trained region encoder to an object detector through transfer learning. A stock object detector like faster RCNN with a ResNet50 backbone is used. This backbone is initialized with the pre-trained region encoder.
The network is now trained on a human-annotated detection dataset like the large vocabulary instance segmentation dataset using standard cross-entropy loss. This allows the pre-trained region encoder backbone, its region proposal head, and the classifier head to refine their weights to match the training dataset.
Zero-Shot Object Detection Inference With RegionCLIP
RegionCLIP achieved state-of-the-art results compared to other similar vision-language models:
It achieved a mean average precision (mAP) of 50.7 on ground-truth regions and mAP of 11.3 on proposed regions, both significantly higher than other models.
It achieved average precision for unseen object categories (APr) of 50.1 on ground-truth regions and 13.8 on proposed regions, again higher than other models.
Overview of Other Approaches
Vision-language models are being innovated at a rapid pace. After RegionCLIP in 2021, many more capable models have come out:
Florence: Florence refines the vision-language approach of CLIP for fine-grained object detection and video retrieval.
X-CLIP: X-CLIP is a vision-language model for videos, but its innovative approach to generating realistic text descriptions using another neural network rather than a fixed set of template phrases sets it apart and makes it potentially useful for zero-shot detection.
Peekaboo: Peekaboo combines a diffusion-based generative algorithm with vision-language models to achieve zero-shot segmentation without any segmentation-specific training.
Use Zero-Shot Object Detection in Your Business
Object detection — the simple task of identifying all the things in a photo, video, or camera feed — has a wide range of uses cutting across industries. For many years, upgrading such systems to handle new objects required technical expertise and cost money.
But modern zero-shot object detection has finally made it accessible, usable, maintenance-free, and future-proof for everyone, even laypeople. No matter what industry you're in or what business you're running, there's a good chance zero-shot object detection can help you save time, money, or effort. Contact us to learn how!
References
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, Gretchen Krueger, Ilya Sutskever (2021). “Learning Transferable Visual Models From Natural Language Supervision”. arXiv:2103.00020 [cs.CV]. https://arxiv.org/abs/2103.00020