Assistants & GPTs like those offered by OpenAi, powered by artificial intelligence (AI) and large language models (LLMs), have greatly improved the productivity of employees and teams across many industries and roles, from engineering to creative professionals.
However, there are several concerns as well. Many companies don't like sending their business data to external chatbots due to security or compliance concerns. Others may not be happy with their subscription costs. Users may hesitate to ask personal questions regarding their health or life to a service controlled by an external company.
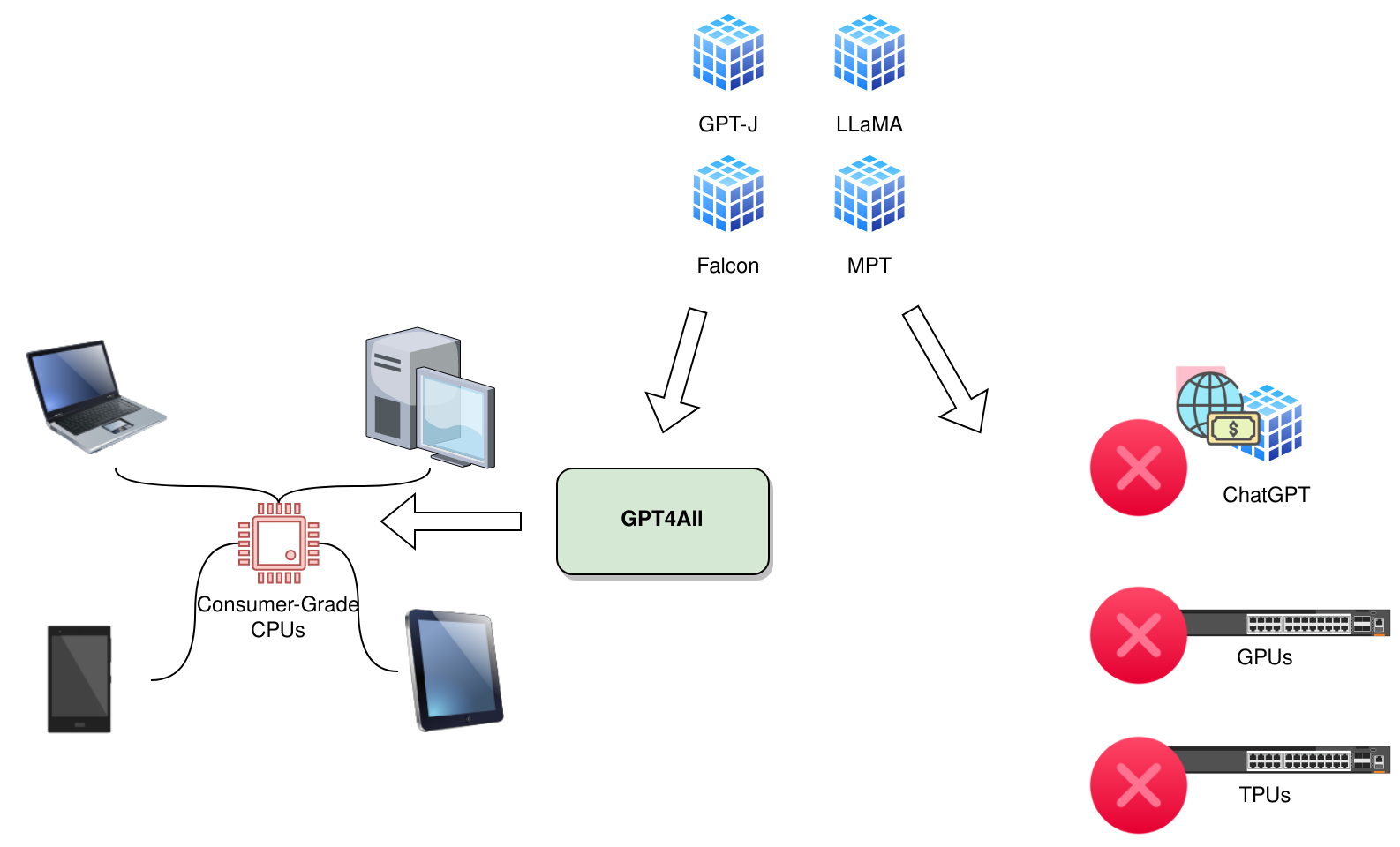
All these concerns are alleviated if anyone can use powerful AI chatbots on their own laptops or mobile devices without sending any data over the network and without using expensive graphics processing units (GPUs) or cloud servers.
In this article, we explore a project called GPT4All that's bringing this vision to reality.
Introduction to the GPT4All Framework
GPT4All is a framework focused on enabling powerful LLMs to run locally on consumer-grade CPUs in laptops, tablets, smartphones, or single-board computers. These LLMs can do everything ChatGPT and GPT Assistants can, including:
Answer questions on just about any topic imaginable
Understand complex documents of personal or professional importance and provide useful answers related to their contents
Help compose emails, documents, stories, poems, or songs
Generate code — even entire applications — using popular programming languages and frameworks
GPT4All provides an ecosystem of building blocks to help you train and deploy customized, locally running, LLM-powered chatbots. These building blocks include:
GPT4All open-source models: The GPT4All LLMs are fine-tuned for assistant-style, multi-turn conversations that can run on commodity CPUs without any need for expensive graphics processing units (GPUs) or tensor processing units.
GPT4All desktop chatbot: The GPT4All desktop assistant-style chatbot can run on commodity processors and popular operating systems like Windows, macOS, and Linux.
GPT4All software components: GPT4All releases chatbot building blocks that third-party applications can use. They include scripts to train and prepare custom models that run on commodity CPUs.
GPT4All dataset: The GPT4All training dataset can be used to train or fine-tune GPT4All models and other chatbot models.
GPT4All is backed by Nomic.ai's team of Yuvanesh Anand, Zach Nussbaum, Brandon Duderstadt, Benjamin Schmidt, Adam Treat, and Andriy Mulyar. They have explained the GPT4All ecosystem and its evolution in three technical reports:
In the following sections, we delve into GPT4All, starting with the most important question: Why?
Benefits of Local Consumer-Grade GPT4All Models
LLM-powered AI assistants like GPT4All that can run locally on consumer-grade hardware and CPUs offer several benefits:
Cost savings: If you're using managed services like OpenAI's ChatGPT, GPT-4, or Bard, you can reduce your monthly subscription costs by switching to such local lightweight models. If you're already using self-hosted models, you can save costs by running them on cheaper CPU machines instead of expensive GPU machines.
Offline accessibility: You can use these models even offline. This is useful for remote environments where internet connectivity or power supply is unreliable.
Improved productivity: They can increase productivity by reducing the time lost connecting to networks, provisioning expensive GPU machines, and using custom client applications.
Data security and privacy: For personal and office use, you can maintain user privacy and data security of your documents without relying on external LLM providers. This is useful in restricted environments like health care and defense, where compliance and confidentiality are paramount.
Fallback solution: In critical use cases where the 24/7 availability of an LLM is essential to your users, you can fallback on GPT4All if multiple retries to an online LLM service fail.
Let's see how the above benefits of GPT4All can potentially play out in various industries.
Health Care
Healthcare professionals may need 24/7 access to different types of knowledge:
Medical research and recommendations
Standard operating procedures and checklists for medical emergencies
Private health data that must comply with national protection regulations
Embedding such knowledge in a capable but lightweight LLM that runs on consumer-grade smartphones and tablets greatly improves its accessibility.
In remote environments or disaster zones where online access may not be practical, this kind of access could be life-saving. It could also be useful when healthcare providers are short on the time and attention needed to dig through dense academic writing.
Law
A lightweight LLM like GPT4All that can run on consumer-grade laptops, tablets, and smartphones can potentially improve the productivity of corporate lawyers, legal researchers, risk and compliance professionals, and interns by enabling them to ask questions about complex legal documents. A GPT4All chatbot could provide answers based on these documents and help professionals better understand their content and implications.
Plus, they can do so without having to upload confidential legal documents to managed LLM services and risking their data security.
Engineering
In industries like offshore oil and gas, merchant shipping, and mining, engineers may need access to industry knowledge from handbooks, training tutorials, checklists, or standard operating procedures without online connectivity. Local lightweight models like GPT4All can help them as well.
GPT4All Models
Let's delve deeper into the mechanics of GPT4All by starting with its models.
The GPT4All models take popular, pre-trained, open-source LLMs and fine-tune them for multi-turn conversations. This is followed by 4-bit quantization of the models so that they can load and run on commodity hardware without large memory or processing requirements. None of these models require GPUs, and most can run in the 4-8 GB of memory common in low-end computers and smartphones.
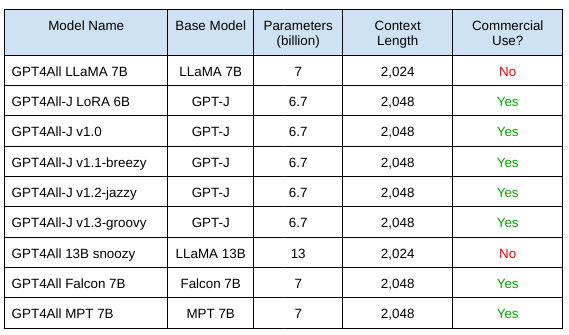
The table below lists some of the available GPT4All models:
Base Models
As of November 2023, GPT4All can fine-tune these transformer-based, pre-trained, base models:
LLaMA: Meta's LLaMA was among the first capable LLMs with publicly available weights. However, it's only licensed for research purposes, not commercial use. GPT4All uses the two LLaMA models that can fit in available commodity hardware:
LLaMA 7B, the seven-billion-parameter model
LLaMA 13B, the 13-billion-parameter model
GPT-J: GPT-J is an open-source, six-billion-parameter model from EleutherAI. Its Apache 2.0 license makes it suitable for commercial uses.
MPT:Mosaic Pretrained Transformer (MPT) is an open-source, 7-billion-parameter model from MosaicML suitable for commercial use.
Falcon:Falcon is a family of open-source LLMs for commercial use. They range from 1.3 billion to 180 billion parameters. GPT4All supports the models with 1.3 billion and 7.5 billion parameters.
Nomic has already prepared GPT4All models from these base models and released them for public use.
GPT4All Model Training
All the GPT4All models were fine-tuned by applying low-rank adaptation (LoRA) techniques to pre-trained checkpoints of base models like LLaMA, GPT-J, MPT, and Falcon. LoRA is a parameter-efficient fine-tuning technique that consumes less memory and processing even when training large billion-parameter models.
What Is 4-Bit Quantization?
The key trick that GPT4All employs to run on consumer hardware is the quantization of model weights. What does quantization do exactly?
A regular transformer model consists of many neural layers like multi-head attention blocks, attention masks, multi-layer perceptron (MLP) layers, and batch normalization layers.
Each layer consists of a set of real numbers that are learned during training. Together, these real numbers from all layers number in the billions and constitute the model's parameters. Each parameter occupies 2-4 bytes of memory and storage and requires GPUs for fast processing.
However, if you compress parameter values down to 4-bit integers, these models can easily fit in consumer-grade memory and run on less powerful CPUs using simple integer arithmetic. Accuracy and precision are reduced, but it's generally not a problem for language tasks. Quantization is just the process of converting the real number parameters of a model to 4-bit integers.
Download GPT4All Models
There are GPT4All models that are already available for download in different formats depending on your use case:
For use with the GPT4All desktop application, download a suitable ".gguf" model file from the GPT4All model explorer. These are available from Nomic.ai as well as other organizations like Nous Research.
For standalone use via the transformers library, download them from the GPT4All Hugging Face hub. You can use the GPT4All converter scripts to convert any of these models to a ".gguf" file for desktop use.
GPT4All vs. Other Models
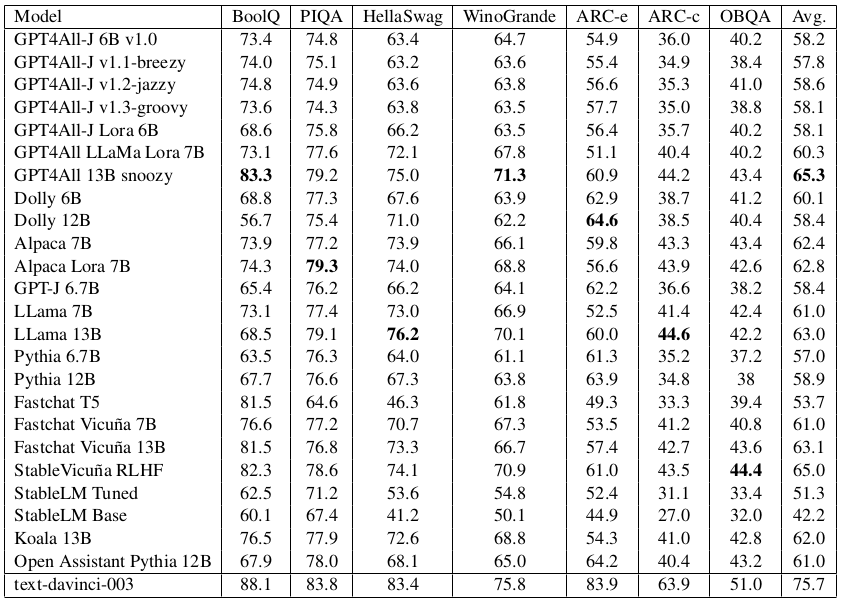
How do GPT4All models compare against other popular open-source LLMs, like Stanford Alpaca or Vicuna, on LLM benchmark tests? Nomic.ai's third technical report contains accuracy metrics on various common-sense reasoning benchmarks, as shown below:
GPT4All vs. other open-source and commercial LLMs (Source: Nomic.ai)
We can see that:
The GPT4All 13B Snoozy model outperforms all the other GPT4All models
GPT4All 13B Snoozy also outperforms its base LLaMA 13B model
LLaMA-based GPT4All models fare better than the ones based on GPT-J on most benchmarks but not all
In general, the smaller GPT4All models are a mixed bag against their base models, GPT-J 6.7B or LLaMA 7B. Some of them have better accuracy, while others don't
Since benchmarks don't offer a full picture, we test some of the GPT4All models qualitatively on various natural language processing (NLP) tasks in a later section.
GPT4All Training Datasets
The training data to fine-tune the GPT4All models for multi-turn conversations consists of:
A large number of prompts from various public datasets (there are between 400,000 to a million prompts, depending on the version)
Responses generated by the first OpenAI ChatGPT model (technically called gpt-3.5-turbo)
This data doesn't contain any manually authored ground truth responses at all. Instead, all the responses are generated using ChatGPT and treated as ground truths. That's why GPT4All is essentially knowledge distillation, with ChatGPT as the teacher model. The base model being fine-tuned — one of LLaMA, GPT-J, MPT, or Falcon — is the student model that learns to mimic ChatGPT's responses.
The Nomic.ai team used Nomic Atlas for data visualization, curation, and cleaning. The cleaned versions are listed below:
First version: This dataset, with 400,000+ prompts, was used to train the first GPT4All LLaMA-based model
v1.0: This is the first GPT4All-J dataset, with 800,000+ prompts, for training the first GPT-J model
v1.1-breezy: The GPT4All-J dataset was cleaned up by removing the stock ChatGPT responses that say it's an AI language model
v1.2-jazzy: Other common responses like "I'm sorry" or "I can't answer" were removed in this version
v1.3-groovy: ShareGPT and Dolly 15K datasets were added and semantically similar prompts were removed, resulting in about 740,000 prompts
All these versions are available under the Apache 2.0 license for any commercial or personal use. However, you should be aware of some caveats:
OpenAI legally prohibits the use of ChatGPT outputs to develop commercial models that compete with OpenAI
Stack Overflow content is originally under a Creative Commons license
GPT4All Software Components
In this section, we explain the GPT4All software components that you can use as building blocks in your web, mobile, desktop, or command-line applications.
GPT4All Backend
The gpt4all-backend component is a C++ library that takes a ".gguf" model and runs model inference on CPUs. It's based on the llama.cpp project and its adaptation of the GGML tensor library. The GGML library provides all the capabilities required for neural network inference, like tensor mathematics, differentiation, machine learning algorithms, optimizer algorithms, and quantization.
In addition, this backend specifically supports loading the supported base models and applying quantization to their model weights.
GPT4All Bindings
The gpt4all-bindings component provides adapters that enable the use of the GPT4All C++ backend from applications and libraries in other languages. The supported languages are:
The gpt4all-api component enables applications to request GPT4All model completions and embeddings via an HTTP application programming interface (API). In fact, the API semantics are fully compatible with OpenAI's API. That means you can use GPT4All models as drop-in replacements for GPT-4 or GPT-3.5.
Code snippet shows the use of GPT4All via the OpenAI client library (Source: GPT4All)
GPT4All Training
The gpt4all-training component provides code, configurations, and scripts to fine-tune custom GPT4All models. It uses frameworks like DeepSpeed and PEFT to scale and optimize the training.
GPT4All Deployment
You can deploy GPT4All in various configurations depending on your use case. These are explained below.
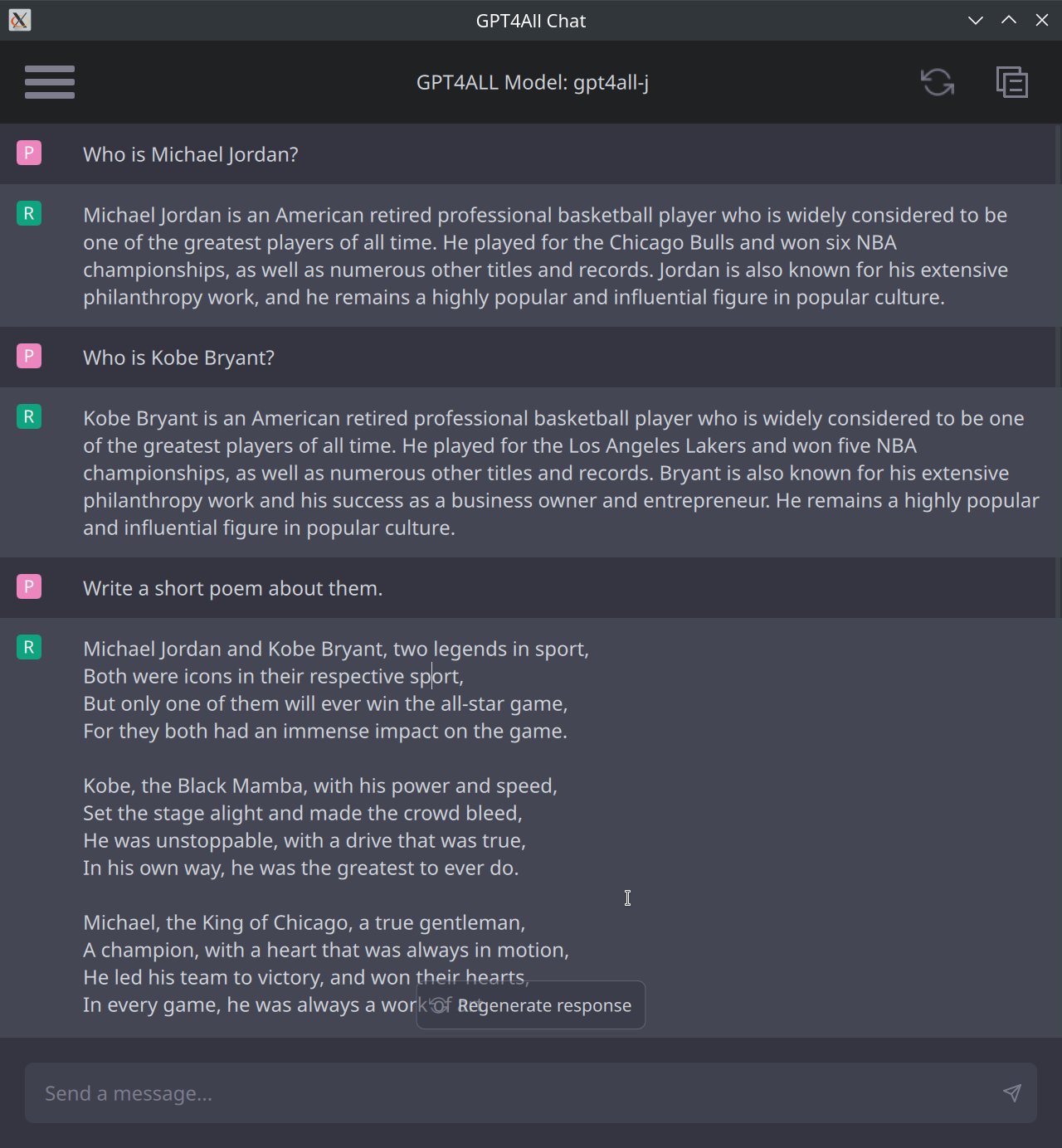
GPT4All Chat Desktop Application
The gpt4all-chat component is a QT-based C++ desktop application with a graphical user interface shown below:
Through this application, laypeople can use any GPT4All chatbot model on their desktop computers or laptops running Windows, macOS, or Linux.
GPT4All Chat Command-Line Tools
You can deploy GPT4All as a command-line interface (CLI) tool for power users. The CLI component provides an example implementation using the GPT4All Python bindings.
GPT4All API Clients
You can deploy GPT4All in a web server associated with any of the supported language bindings. The API component provides OpenAI-compatible HTTP API for any web, desktop, or mobile client application.
This option is suitable for deployment in a corporate intranet where you may want all employees to use a shared GPT4All model but also restrict data transfers to the intranet.
LangChain Integration
If your application uses LangChain, you can easily use a GPT4All model because LangChain has built-in support for GPT4All models.
Testing GPT4All for Medical and Legal NLP Tasks
We tried GPT4All on a medical report summarization task and a legal clause identification task. For these tests, we tried three of its models:
Mistral Instruct with 7 billion parameters based on the Mistral-7B model
GPT4All Snoozy with 13 billion parameters based on the LLaMA-13B model
Falcon-7b with 7 billion parameters
Medical Report Summarization
We selected a medical report from the medical transcriptions dataset which is about 12,800 characters or 2,635 tokens. A part of the report is shown below:
However, every model was taking a considerable time — more than 15+ minutes — to summarize the full report on a 4-core, 32-GB RAM, server-grade machine. Since GPT4All is supposed to be for day-to-day use, that was unacceptable performance. So, we cropped the report down to about 5,000 characters to be able to judge the quality of the summaries in reasonable time. We gave the following instruction in the prompt: "Summarize this medical report with accuracy and covering all information."
GPT4All's Mistral Instruct model (7 billion parameters, 4 GB RAM) generated this summary:
It's a fairly good summary that followed our instructions to cover all aspects and stick to the facts in the report.
The GPT4All Snoozy model (13 billion parameters, 9 GB RAM) generated this summary:
This too is a fairly good summary though arguably not as good as the previous one.
The third model we tested, GPT4All Falcon-7b, basically failed. It produced just two sentences of summary with just basic details of the patient. The last sentence was incomplete, suggesting issues with alignment training.
Legal Clause Identification
We gave GPT4All a task in the field of law by asking it to identify legal clauses of a certain type in a legal agreement.
We initially supplied the full agreement of around 11,430 characters or around 2,500 tokens, and asked it to identify data and time related conditions. However, this took considerable time of 27+ minutes without any reply at all.
So we cropped it down to this 2,000-character snippet to keep the testing practical:
For the first prompt — "Identify date and time related conditions in this legal agreement snippet" — the Mistral Instruct model gave this answer within a minute:
You can see that it misunderstood the prompt and generated a factually incorrect answer.
So we changed the prompt to "Identify deadlines in that agreement." This gave the following response:
The first point in that response is an accurate answer. However, the second point isn't identifying a deadline but explaining what happens if they miss it. The last point is irrelevant to our request.
It also missed the deadline of two working days in the snippet.
Overall, the quality of GPT4All responses to such tasks are rather mediocre — not so bad that it's best to stay away but definitely calls for thorough prior testing for your user cases.
Limitations of GPT4All
The GPT4All project has some known limitations as of now:
Slow performance and high resource consumption: Even with quantization, GPT4All is quite slow when processing long prompts. A 2-core, 16-GB, EPYC Windows server was very slow on the medical report summarization task. After upgrading to a 4-core, 32-GB, EPYC CPU Windows server, we observed the following performance and resource consumption numbers:
Doesn't use GPU: The components that GPT4All depends on, like llama.cpp and GGML, have only limited experimental support for running on GPUs. Plus, GPT4All depends on their older versions, which don't have even limited support.
Multilingual capabilities: The fine-tuning datasets are overwhelmingly English only. As of now, there's no systematic support for other languages either in the dataset or in the base models.
GPT4All Opens Up New Possibilities
The GPT4All project aims to make its vision of running powerful LLMs on personal devices a reality. Mainstream LLMs tend to focus on improving their capabilities by scaling up their hardware footprint. In doing so, such AI models become increasingly inaccessible even to many business customers.
Projects like GPT4All fill that gap by shrinking down those powerful LLMs to run on off-the-shelf commodity devices. They improve not just accessibility but also productivity.
Contact us if you want to implement such innovative solutions for your business.