New large language models (LLMs) with various architectural improvements are being created and published practically every month. In this shootout, we try to find which is the best open-source LLM for summarization and chatbot use cases as of November 2023.
Definitions
First, an overview of the terminology we'll be using since the term "open-source LLM" can mean different things to different people:
Does it imply the neural network's actual code is published? For example, can any developer study the code that creates its layers using PyTorch or TensorFlow semantics, or read the code to fine-tune it using low-rank adaptation?
Does it mean the model's weights are publicly and legally available for download by anyone?
Does it imply the model's weights can not only be downloaded by anyone but also used for any purpose?
Is commercial use implied?
In this article, we use "open-source LLM" in two senses. First, we use it as an umbrella term that covers all these possibilities.
Second, we use the term "open-source" if the LLM's actual code, like the example given above, is available publicly on GitHub or some other repository. In addition, it implies that such code also includes scripts to train, test, or fine-tune the model based on the same methodology used by the authors. However, when required in tables and elsewhere, we use it to specifically imply that its code is published.
We also employ two other terms to disambiguate:
Open-access LLM: Open access here means the model weights are available publicly on Hugging Face, GitHub, Google Drive, or similar services. However, it doesn't automatically imply that you can use the model for commercial purposes; many models only permit research or personal uses.
Commercial-use LLM: This implies that the LLM is not only open-access but also permits commercial uses.
Combinations of these terms enable accurate descriptions of any model. For example, an open-source, closed-access, non-commercial LLM implies that its code is published but the model weights aren't, and even if you train your own model using that code, its commercial use isn't allowed.
What is Best Open-Source LLM for Long Text Summarization?
For long text summarization, a pretrained, foundation model LLM must be fine-tuned for instruction-following. The goal of this is to help the LLM have a better understanding of what a quality output for a given instruction set looks like. This helps the model differentiate the summaries between prompt language such as:
Write a 5 word summary that focuses on “xyz”
Write a 5 word extractive summary that focuses on “xyz” in the tone “x”
The underlying model probably doesn’t have a very deep understanding of what differentiates the two based on tone and the type of summary. This fine-tuning of showing the instructions and the summary output improves this relationship.
Preferably, the LLM should be further fine-tuned for human alignment — that is, the ability to match typical human preferences — using techniques like reinforcement learning from human feedback (RLHF) or direct preference optimization.
In the following sections, we explain how we tested prominent open-source LLMs on long text abstractive and extractive summarization tasks and what the results look like.
Methodology
First, we had to shortlist the LLMs to test. For this, we first categorized LLMs into three size-based groups based on how they're used by different customer segments:
Models with 30 billion or more parameters: A common rule of thumb is that bigger models produce better responses and cause fewer problems like hallucinations or repetitive generation. That's why companies prefer the biggest LLMs for production use cases where high quality is essential. These massive LLMs require powerful server-grade GPUs and are deployed on scalable clusters to serve hundreds to thousands of users.
Models with 10-20 billion parameters: This range is a sweet spot for companies and professionals because these models are fairly capable without requiring high-end hardware and enable consistency between development and production environments. Models near the upper end of the range can run on current low-end server-grade GPUs, while those at the lower end can run on consumer-grade GPUs.
Models below 10 billion parameters: These models can run on mid-range consumer-grade hardware, even plain CPUs without any GPUs. This makes them ideal for day-to-day use by employees at their workstations. Using tricks like quantization, they can even run on mobile devices.
Next, the models under each category were shortlisted using public leaderboards that compare their performance on various tasks and benchmarks using automated testing.
With the models decided, we selected three domains where summarization is frequently necessary for both business and personal uses:
Health care: Health care professionals are often short on time and need accurate summaries of entire medical reports or particular sections of them.
Law: Summaries of legal documents and legal proceedings are helpful to a variety of legal professionals to improve their productivity.
Long-form content: Summarizing long-form nonfiction content is useful for many roles including media professionals, researchers, and academics.
For each domain, we selected a long-text dataset and picked an example that is representative of documents and reports in its respective field.
Finally, we requested the shortlisted models to summarize our test documents with the same prompts and the same chunk size for a recursive chunking strategy. The prompts asked the models to ensure factual accuracy and completeness.
Our prompt for abstractive summarization was: "Write a summary that is factually accurate and covers all important information for the following text."
For extractive summarization, our prompt was: "Select between 2 and 6 important sentences verbatim from every section of this text that convey all the main ideas of the section."
Unfortunately, the deployment of models isn't a solved problem as yet. There's no single service where every LLM is readily available or easily deployable. Hugging Face comes close, but other LLM service providers like Replicate or SageMaker can be more convenient or performant for some models. We used the most convenient option for each model.
We explain the testing in more detail in the following sections.
What the LLM Leaderboards Say
We used the scores on two popular leaderboards as qualifying criteria to shortlist the open-source LLMs to test.
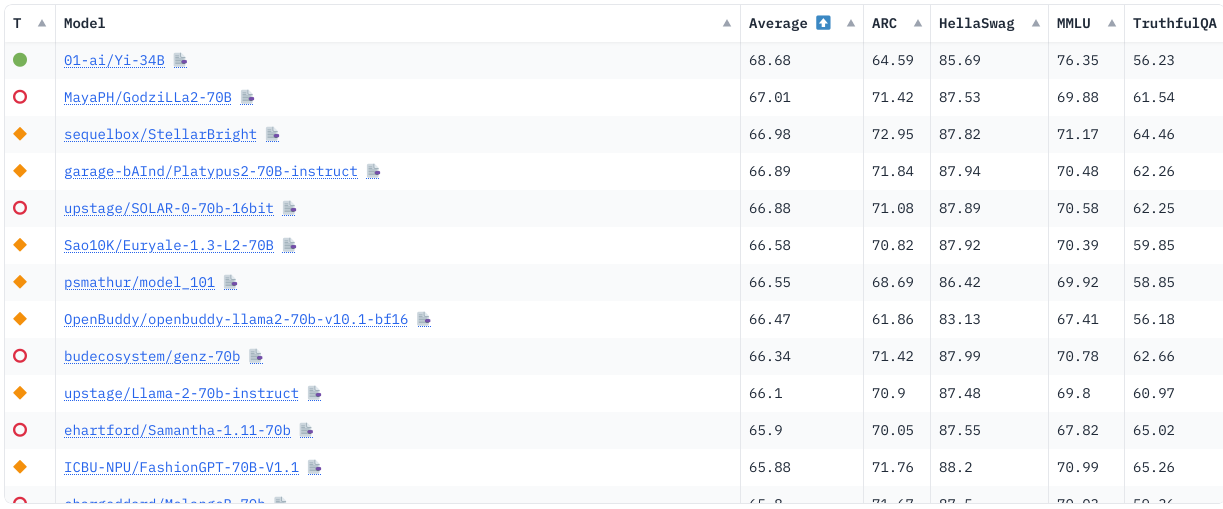
1. Hugging Face Open LLM Leaderboard
Hugging Face open LLM leaderboard (Source: Hugging Face)
Common-sense reasoning through benchmarks like HellaSwag and ARC
Language understanding using benchmarks like the Massive Multitask Language Understanding (MMLU)
Knowledge understanding through benchmarks like TruthfulQA
Many of the names on this leaderboard may seem unfamiliar. But when you dig into their details and descriptions, you find that they're fine-tuned versions of popular foundation models like Llama 2.
2. GPT4All
Another helpful leaderboard for the best open-source LLMs is the GPT4All project since it focuses on the optimization of open-source LLMs for everyday use on consumer-grade hardware and mobile devices.
Part of the selected medical report (Source: Kaggle)
Legal Documents
The longest legal document in the contract understanding Atticus dataset (CUAD) was selected. This article has 60,000+ tokens, making it a challenge for good quality summarization with ample coverage:
Part of the selected legal document (Source: CUAD)
Non-Fiction Long-Form Text
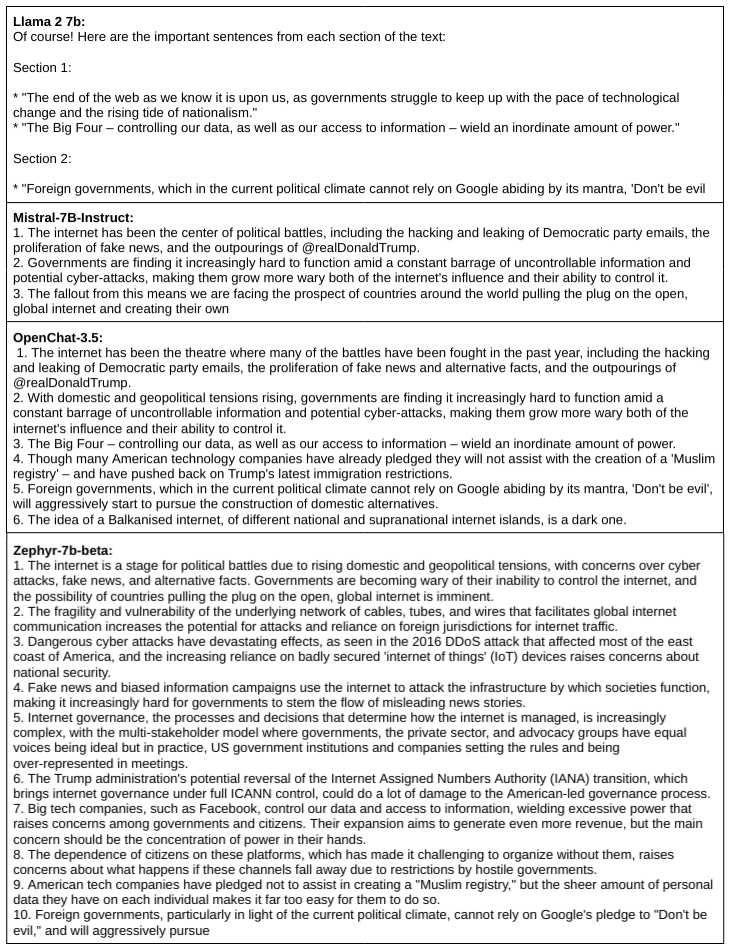
We selected the following article, titled "The end of the web," from the "question answering with long input texts, yes!" (QuALITY) dataset because such a vague yet ominous title compels many readers to seek a summary of what the article is all about.
We describe how the 30B+ LLMs, favored by serious businesses that want high-quality results all the time, fared.
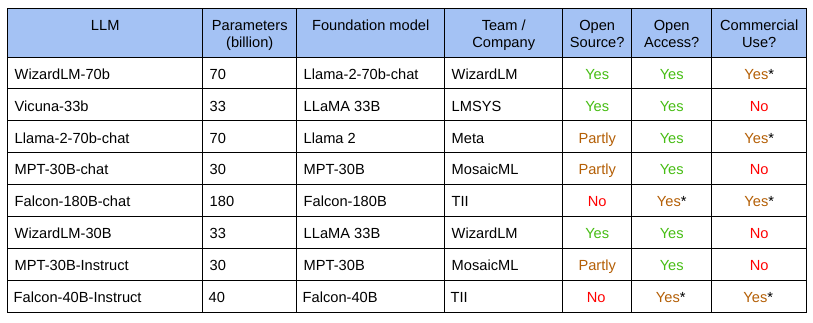
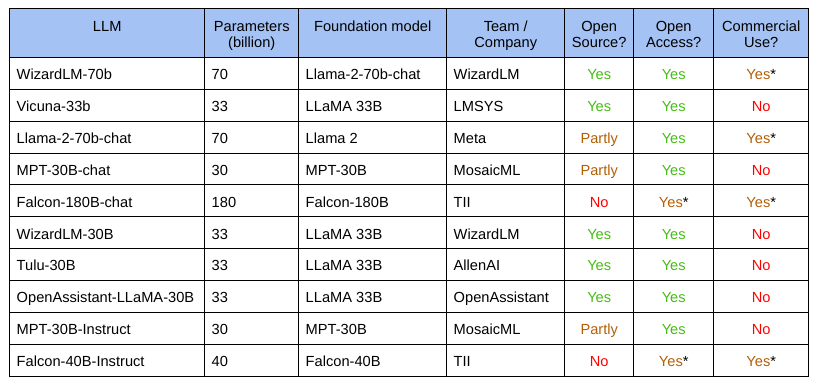
The Contenders
Training an LLM with 30 billion or more parameters isn't trivial in terms of infrastructure requirements and expenses. That's why there aren't too many of them. The available contenders are listed below:
The asterisks imply that commercial use may come with riders. For example, Llama 2 doesn't use a well-known open-source license like the Apache 2.0 license but instead specifies its own Llama 2 Community License. For some models, you need to submit a form to obtain access.
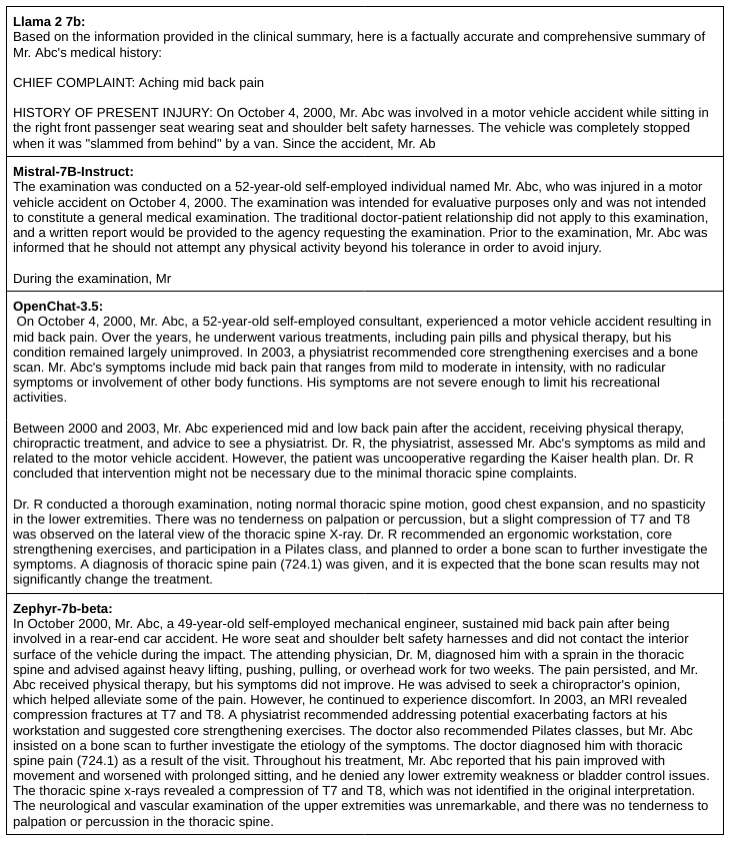
Medical Report Abstract Summaries from 30B+ LLMs
Except for MPT-30B, none of the medical report summaries turned out well. Two of the models failed completely while the Llama 2 70b model didn't fare well on completeness.
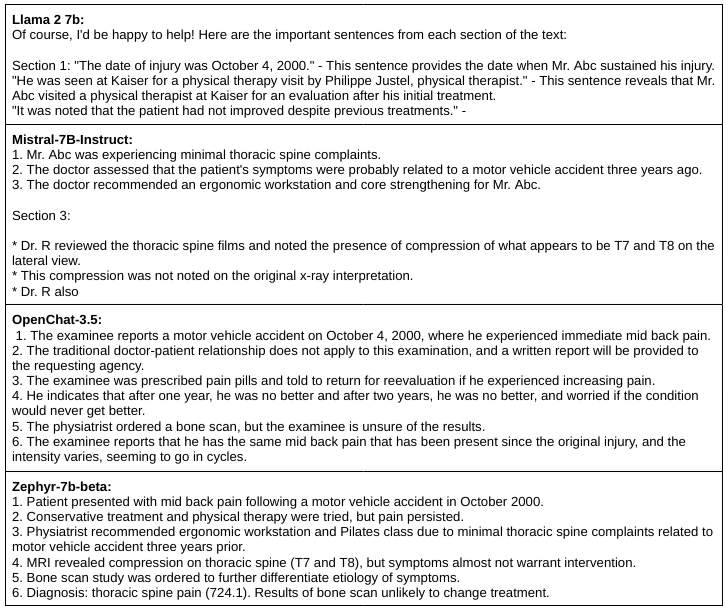
Medical Report Extractive Summaries from 30B+ LLMs
The extractive summaries for the medical report came out like this:
Llama 2 was on the right track but needed a maximum token setting that was proportional to the report length.
MPT-30B didn't follow the instructions and produced a one-line abstract summary instead.
Falcon-40B failed.
Vicuna-33B generated an abstract and incomplete summary.
Legal Document Abstract Summaries from 30B+ LLMs
The summaries for the legal document are shown below:
The MPT-30B produced the best summary.
The Falcon-40B model generated a good one but with unwanted HTML tags.
Llama 2 70b doesn't look that good in terms of completeness. However, this was the first test and used a different prompt than all the other models; so that might have played a part.
The Vicuna-33B model has a runtime failure which was probably due to badly formatted or empty output.
Legal Document Extractive Summaries from 30B+ LLMs
The extractive legal summaries looked like this:
Only Llama 2 produced an extractive summary.
Both MPT-30B and Falcon-40B ignored the instructions and generated abstract summaries.
Vicuna-33B errored out, possibly due to deployment issues rather than content problems.
Long-Form Text Abstract Summaries from 30B+ LLMs
A qualitative analysis of the summaries for the long-form articles brings up the following observations:
Llama 2 follows the prompt instruction to ensure factual accuracy and completeness. They are qualitatively better.
MPT-30B also produced a good summary.
Falcon-40B-Instruct seems to handwave the task with a very general summary instead of mentioning specifics. This may be because it's just tuned for instruction-following rather than human alignment.
The Vicuna-33B model has gone badly astray here.
Long-Form Text Extractive Summaries from 30B+ LLMs
The extractive summaries looked like this:
Llama 2 followed the instructions correctly but its maximum tokens must be set carefully to obtain complete summaries.
MPT-30B ignored the instructions and generated an abstract summary.
Falcon-40B hallucinated an entirely irrelevant summary.
Vicuna-33B was on the right track but incomplete.
Text Summarization Using 10-20B Open-Source LLMs
These LLMs are popular because they can run low-end server-grade and high-end consumer-grade hardware. But how do they fare on quality compared to the largest LLMs? We explored this question in the sections below.
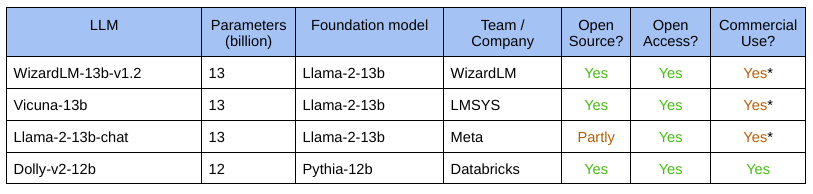
The Contenders
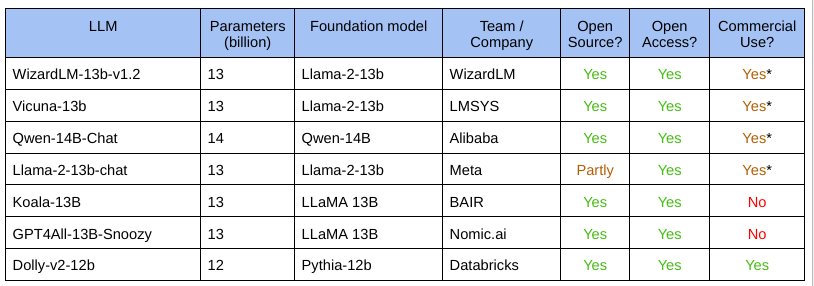
Most of these models are instruction-tuned, or even RLHF-aligned, improvements on foundation models like the Llama 2 13B model. Some of the important contenders are shown below:
The list is heavily dominated by the Llama 2 13-billion parameter model. An interesting entry here is the Dolly v2 model that we've analyzed before.
The qualitative analysis of these summaries is interested in two aspects:
How do they compare with one another?
How do they compare against the larger siblings in their own families?
Medical Report Abstract Summaries from 10-20B LLMs
The medical summaries looked like this:
Llama 2 was doing a decent job and probably would have generated a decent summary but for the maximum token limit we set.
Vicuna seemed to have recognized the medical aspect of the text but failed to process it correctly.
Medical Report Extractive Summaries from 10-20B LLMs
The extractive medical summaries came out like this:
Llama 2 was on the right track here. Only its maximum tokens parameter needs to be better adjusted to the input length.
The statements included by Vicuna were not from the supplied medical report. It appeared to be hallucinating.
Legal Document Abstract Summaries from 10-20B LLMs
Both Llama 2 13-billion model and its fine-tuned Vicuna-13b did badly on the legal summaries. The Llama 2 model was very incomplete. The Vicuna model produced something entirely irrelevant.
Legal Document Extractive Summaries from 10-20B LLMs
The 10-20B LLMs generated these extractive summaries for the same legal agreement:
The LLama 2 13B model didn't select the most important sentences in the document.
Vicuna again produced irrelevant text.
Long-Form Text Abstract Summaries from 10-20B LLMs
The Llama 2 model did a decent job on the long-form article. However, Vicuna got it so wrong that we had to verify if we had provided the correct article as input; we had! Exactly why it hallucinated about memory palace techniques is difficult to explain but precisely the kind of complication you wouldn't want in day-to-day use.
Long-Form Text Extractive Summaries from 10-20B LLMs
The extractive summaries weren't impressive overall:
Llama 2 was on the right track. But we have to set its maximum tokens carefully according to the length of the input to obtain good extractive summaries.
Vicuna hallucinated an irrelevant summary.
Text Summarization With Sub-10B Open-Source LLMs
These are the smallest modern LLMs that can run on regular consumer-grade CPUs and even mobile devices with acceptable latencies.
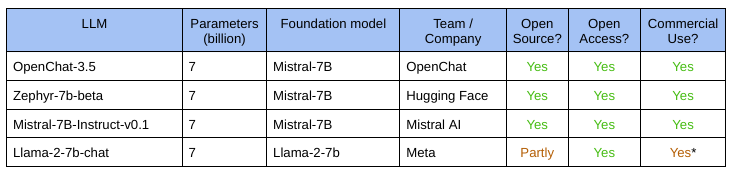
The Contenders
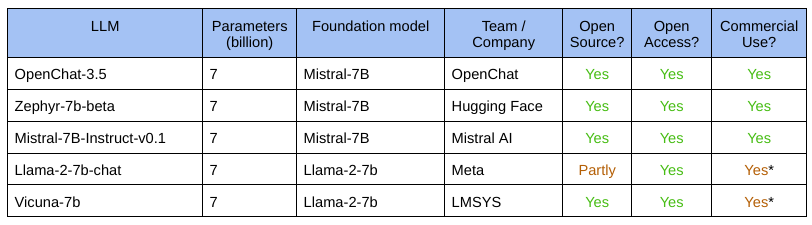
Since training these sub-10-billion models is relatively easier, there are a lot more contenders in the space. We selected these four top-ranking LLMs for the showdown:
Smaller LLMs often don't fare well on many tasks. They can produce results that are mediocre, plain wrong, or badly formatted to be usable. But for day-to-day business or personal use, they may be good enough most of the time. We made the observations below.
Medical Report Abstract Summaries from Sub-10B LLMs
First, the medical report summaries:
OpenChat and Zephyr produced very detailed and complete summaries.
Medical Report Extractive Summaries from Sub-10B LLMs
The extractive summaries for the medical reports came out like this:
Llama 2 had picked key sentences but also included explanations for them.
Neither Llama 2 nor Mistral satisfied completeness.
Both OpenChat and Zephyr satisfied completeness better.
Legal Document Abstract Summaries from Sub-10B LLMs
The legal summaries look like this:
Notice how all three Mistral-based LLMs have attempted to produce informative and complete summaries.
Zephyr, in particular, has produced a stellar summary of the entire document here.
Legal Document Extractive Summaries from Sub-10B LLMs
The sub-10B LLMs produced these extractive summaries for the legal agreement:
Along with the extracted key points, Llama 2 had included brief explanations. This may not be what you want in production. A little playing around with the prompt may help.
Mistral's summary wasn't complete. It seems like it's not as good at extractive summaries as abstract ones.
Both OpenChat and Zephyr followed the instructions perfectly again and generated summaries that are complete.
Long-Form Text Abstract Summaries from Sub-10B LLMs
For the long-form articles, the sub-10B LLMs produced these abstract summaries:
All of them are great summaries. In fact, they show better quality than the bigger LLMs.
Both Zephyr and OpenChat seem to follow the prompt instructions well. Clearly, they've attempted completeness in their summaries.
Long-Form Text Extractive Summaries from Sub-10B LLMs
For the long-form articles, the sub-10B LLMs produced these extractive summaries:
Neither Llama 2 nor Mistral produced summaries that were complete.
In contrast, both OpenChat and Zephyr produced comprehensive extractive summaries.
Final Thoughts on Text Summarization Results
The qualitative results show that the Mistral-based OpenChat and Zephyr LLMs, though small, produce excellent results. If their training is scaled up to bigger LLMs, they'll likely outperform all other LLMs.
A note on Vicuna-33B performance: In all these tests, Vicuna didn't perform well. However, readers shouldn't assume that the model is bad. The bad performance here may simply be a consequence of faulty deployment of the model on the LLM-as-a-service we used for these tests, which only goes to highlight the inherent and emergent complexities of using LLMs. Vicuna in fact ranks high on the chatbot leaderboards as you'll see in the sections below.
Tips for High-Quality Text Summarization Using Open-Source LLMs
We can't emphasize this enough: To get close to ChatGPT and even surpass it in quality, always fine-tune your open-source LLMs for your domain, domain terminology, and content structures! The base open-source LLMs can never produce the best quality summaries you need because of their generic training. Instead, plan for both supervised and RLHF fine-tuning to condition the LLM to your domain's concepts as well as your users' expectations of summary structures and quality of information.
Another technique to improve the quality of summaries is to be smart about how you chunk your documents. The first level of chunking should break the document into logical sections that are natural to your domain's documents. Subsequent levels can target subsections if possible or default to token-based chunking.
Finally, better prompting strategies like PEARL can first reason about the content before summarizing, and improve the overall quality.
Best Open-Source LLM for Chatbot Use Cases
Chatbots powered by the best open-source LLMs are potentially very useful for improving the quality of customer service, especially for small and medium businesses that can't afford to provide high-quality 24x7 service. Such chatbots are also useful in making employee services more helpful and less confusing, regarding topics like employee benefits or insurance policy registration.
In these sections, we try to determine which open-source LLM with chatbot capabilities fares well.
Methodology
Leaderboards like the LMSYS chatbot arena and MT-Bench specifically test chatbot capabilities like multi-turn conversations and alignment with human preferences. In addition, the leaderboards we saw earlier provide clues on which LLMs are likely to perform better.
Like before, we divide the LLMs into three categories. For each category, we observe what the leaderboards say.
Chatbot LLMs with 30+ Billion Parameters
In this category, there are more than 10 contenders. However, we exclude any model that seems to be a hobby project of a single individual (like Guanaco) or is finetuned for some other specific task (like CodeLlama). Since most companies won't take the risk of using an individual hobbyist's model or a model trained for some other task, this exclusion is reasonable.
Observations:
WizardLM uses a novel dataset-generating technique to better its foundation Llama 2 model.
Surprisingly, the massive 180 billion Falcon model doesn't score the most.
Why does the older LLaMA 33B foundation model dominate here while the newer Llama 2 model fared better in the previous leaderboards? That may simply be because Llama 2 has been available for a shorter time. We can expect it to dominate in the future.
Chatbot LLMs in the 10-20 Billion Parameter Category
Though there are many more LLMs in this category than shown below, we don't recommend using anything other than one of the top-scoring models. Overall, LLMs based on the Llama 2 13B model do well in this category.
Chatbot LLMs in the Sub-10 Billion Category
There are a lot of contenders in this category. But given that the top-ranking ones already perform extremely well compared to larger models and are available for commercial use, you can avoid any of the other lower-ranking LLMs.
Observations:
Although they're small, with just 7 billion parameters, both OpenChat and Zephyr punch far above their weight, ranking alongside the best four open-source LLMs with 30+ billion parameters.
Which Is the Best Open-Source LLM?
In this article, you saw the various open-source LLM options available to you for customization and self-hosting. As of November 2023, we find that Llama 2 dominates all the leaderboards through its derived models. With a foundation model in each size category, you can expect high-quality results for any use case by picking it.
However, we find that Mistral 7B, and particularly its two derivatives, OpenChat and Zephyr, work unbelievably well in the sub-10 billion category. They're also commercial-friendly. If you want to boost your business workflows with such powerful LLMs that can run on your employees' workstations and mobile devices fine-tuned to your needs with complete data confidentiality and data security, contact us for a consultation!