Manually converting unstructured text such as documents, invoices, emails, reports, and other textual data to structured data that provides insights is a huge part of most business workflows. The problem on top of that is that manual processing of this data requires a huge amount of time and capital resources. This is is an issue across industries, as Gartner predicts that 80 to 90% of all enterprise data is not in a structured format. As 70% of organizations shift their focus to small and wide data instead of big data the ability to generate structured data will only grow.
Natural language processing (NLP) algorithms give us the ability to automate these business workflows to extra the key information we’re looking for from unstructured text instantly. These NLP pipelines can be customized to fit a wide variety of use cases and structured data goals that an organization wants to meet. Let’s look at a number of the most popular ways to convert unstructured text to structured data with modern NLP.
1. Named Entity Recognition With SpaCy
Named entity recognition (NER) is the process of finding and extracting key named entities such as a person, business, location, date etc from unstructured text. At a high level a named entity can be a single word or phrase that refers to something and has attached value. NER pipelines are built using a series of NLP approaches that combine to help lead to an understanding of meaning for a given word in a sentence. This is probably the most popular method of creating structured data from text as it’s extremely easy to customize for your use case and add new entities that you care about. Here’s a few easy ones:
Organizations:
Apple, Microsoft, Width.ai, Twitter, Capital One
NER uses structured entities vs other data extraction methods.
Locations:
Washington DC, 1000 Bank St, Richmond, VA 23218, Portland Oregon
Amounts of Money:
200 dollars, $200, 200 Euros, $200 Great Britain Pounds
SpaCy is an open-source NLP library ready for production use right out of the box. It contains a number of pretrained models for NER and also provides an easy pipeline architecture that let’s you leverage components such as part-of-speech tagging, text classification, lemmatization, entity linking, and more to analyze unstructured data. All of these can be added to a pipeline for quick use in a few clicks, and have the flexibility to be fine-tuned on your specific data and entities. SpaCy is also built using Cython with multiple memory optimization techniques so it’s very fast on a number of architectures. We use spaCy all the time to spin up pipelines to grab quick insights from large unstructured databases.
Use Case Example of Extracting Data
Legal Document cover sheet information extraction (More information)
We used spaCy + a number of other deep learning based models to build an entity extraction pipeline for legal document cover sheets. This pipeline grabs key court case information such as the plaintiff, defendants, case number, court name, attorneys, and more. The baseline architecture supports over 50 different cover sheet formats and is trained on a huge text corpus.
The pipeline reaches our NER after extracting all text unstructured from the cover sheet via OCR and other modules. A custom built spaCy pipeline is then used to turn the unstructured legal document cover sheet into named entities.
2. Keyword Extraction With GPT-3
Keyword extraction is the process of extracting important or relevant keywords from unstructured text. This is considered slightly different from NER as these keywords do not need to have specific labels attached and do not need nearly the level of per class natural language understanding through tools such as lemmatization and POS tagging that a NER model requires. In simple use cases this can be simply words or phrases that match a specific pattern.
High level keyword extraction work can be used to generate keywords that are not found in the unstructured text but are related to it through some learned relationship. These can be semantically or contextual similar keywords, topics discussed, or other methods that enhance your understanding of the data in a few words.
GPT-3 is an autoregressive large language model built by OpenAi. The model is considered task agnostic as the underlying pretrained model is not built for any one specific NLP task but learns the specific task through in-context learning. This is described as feeding the model a sequence of text describing the task at hand and the model outputs the results of the task to its best ability. This is enhanced by adding examples of how to solve the specific task to the input as the model learns on the fly what task you’re trying to accomplish and how to get there.
The task is described and a few examples of how to reach the correct result are included. Example from Stanford Ai
This case study describes how you can process unstructured data such as college course information into different database fields with keyword extraction. The 91% accurate product learns what keywords matter from the input text through an NLP pipeline that uses a GPT-3 model at the core. On top of the normal keywords that are pulled, we generate “higher-order” keywords that are contextually similar to the input text. These enhance the amount of data we have for each record. If you’re just looking to extract data at a high level to start, then perform higher level data analysis, this is a great place to start.
3. Text Classification With BERT
Text classification is a field of natural language processing focused on classifying a body of unstructured text into a predefined class. This can be as few as 2 classes (seen in sentiment analysis) or 1,000s based on your use case.
Bidirectional Encoder Representations from Transformers (BERT) is a transformer based deep learning architecture used for a wide variety of NLP tasks. The model is pretrained on over 2.5 billion words across multiple corpora. From an architecture perspective the main difference between the transformer BERT model and an autoregressive language model such as GPT-3 is that BERT does not have a decoder and instead has a stack of 12 encoders. BERT is adjusted to be used for text classification by adding a classification layer on top of the transformer output.
Once we’ve fine-tuned the pretrained model for text classification we can start running new documents through. Keep in mind that that baseline BERT architecture allows for up to 512 tokens at once, different from the GPT-3 token limit of 2048.
Architecture for classifying text with BERT from Tensorflow
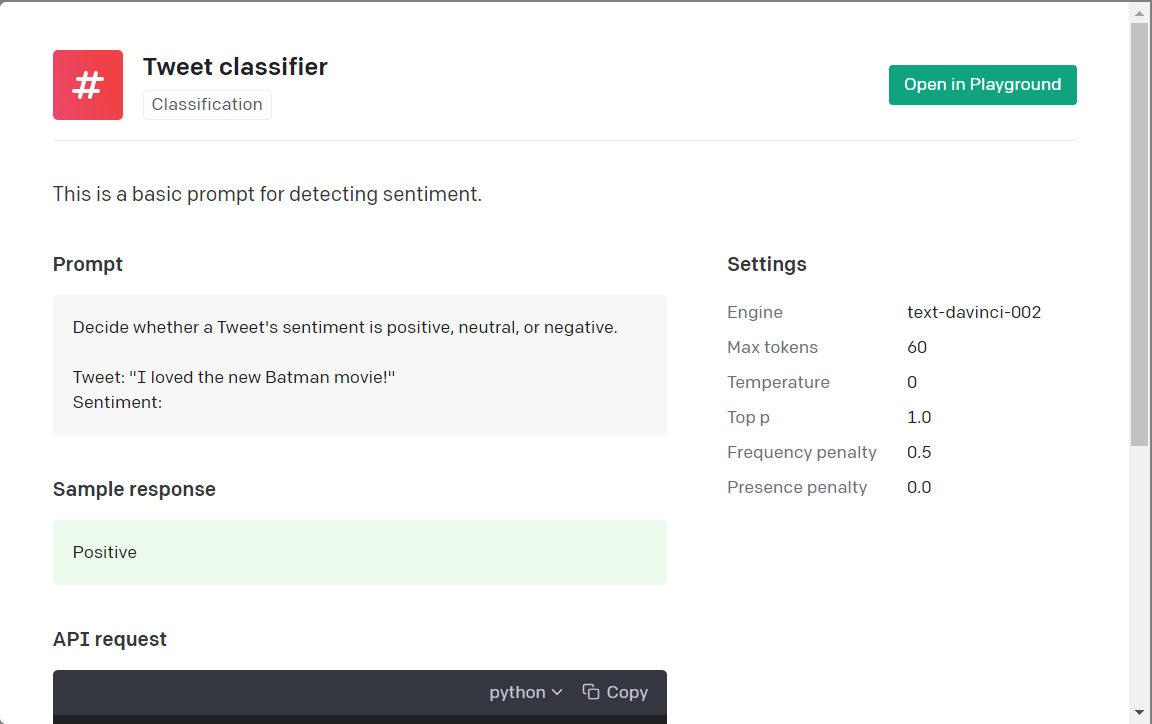
4. Sentiment Analysis With GPT-3
Sentiment analysis allows us to perform structured and unstructured data analysis to understand the underlying sentiment in text. As industries such as customer support, customer relationship management, and competitor analysis continue to add more artificial intelligence and machine learning sentiment analysis becomes more valuable. Understanding the sentiment of a customers message allows you to automatically process there support request or move them to the proper bucket based on the sentiment.
Companies are also using sentiment analysis to build out deep analytics on there products based on customer sentiment in reviews. By understanding how users feel about your products at a high level can help decide business strategy and cluster reviews for further analysis.
GPT-3 allows us to quickly build simple or complex sentiment analysis models for any level of training data. The ability to use just a few prompt examples of relevant unstructured text makes it super easy to deploy a model and start generating sentiment analysis. One of the key benefits of using GPT-3 for this task is that the davinci engine already has a pretty decent understanding of sentiment analysis out of the box. As you can see in the example above we use a simple header defining the task (sentiment analysis) and can already start generating responses even with zero examples. Of course the example above is pretty simple and harder and longer unstructured text will need more examples and/or fine-tuning.
We built a production level twitter sentiment analysis product using GPT-3 and other NLP models. The model focuses on maximizing data variance coverage past simple tweets or tweets that are not used in a customer service setting. Understanding how to read sentiment on a deeper level than just keywords and strong language is the path for a high accuracy sentiment analysis product. We mostly focused on the Sentiment140 dataset, but worked in a few domain specific datasets as well.
5. Convert Unstructured Data to Tabular Data With GPT-3
GPT-3 can be used to create tables with columns and rows from unstructured text with just a few examples showing what the columns mean relative to the row value. Take this input legal summary from a court case.
Through few-shot learning in GPT-3 we an extract specfic information in a table structure:
The crazy part is the document never mentions who is each column in the document. Nowhere in there does it say who the plaintiff or defendant is, or what a Filer is. The Model learns this relationship through it’s training. This is a great way to create a table from unstructured text quickly for a wide variety of use cases without a ton of data sources.
Conclusion
The ability to convert unstructured data into valuable enterprise insights through data cleaning and natural language processing is quickly becoming one of the most important processes required for scaling in many industries. Such data contains so many valuable insights that can help you make better business decisions through having a better grasp on your organization and the abilities of products and services. These processes are often done manually right now which as you know is time consuming and resource intensive.
Width.ai builds NLP based architectures that can help you automate these workflows and start turning your structured and unstructured data into enterprise insights today. Want to learn more about structured data conversion? Check out our other blog posts or reach out for a demo!