Prompt engineering is all about looking for ways to improve the quality and accuracy of results from large language models (LLMs). In recent months, advances like chain-of-thought prompting have enabled prompt engineers to improve the quality of their results. In this article, we look at another prompting technique called ReAct prompting that helps your LLMs really understand how to reach our goal state output and further the understanding of the prompting instructions.
What Is ReAct Prompting?
ReAct is an LLM prompting and result-processing approach that combines reasoning, action planning, and integration of sources of knowledge to make the LLM go beyond its language model and use information from the real world in its predictions. ReAct is a combination of reasoning and acting.
The paper that introduced ReAct showed it to be better than chain-of-thought prompting. Unlike the latter, ReAct does not hallucinate facts as much. However, for the best results, the paper suggests combining ReAct and chain-of-thought prompting with self-consistency checks.
How to Use ReAct Prompting for Your Use Cases
ReAct components
You can implement ReAct prompting for any LLM workflow that involves reasoning, decision-making, action planning, and external knowledge. You need the following key components for ReAct.
1. Provide a ReAct Instruction Prompt for Reasoning and Action Planning
An example ReAct prompt with its components is shown below:
The prompt must contain four key pieces of information for the LLM:
Primary prompt instruction: The prompt must provide a main instruction for the LLM. This is used in pretty much every prompting framework. The goal is to start the model's understanding of what we actually want it to do.
ReAct steps: Specify the steps for reasoning and action planning. "Interleaving thought, action, and observation steps" is a standard sequence you can use in all your ReAct prompts. Some of the versions of this we’ve built use a much more specific Thought section that fully outlines how to think about the task and key information to focus on. This is similar to the system prompts you outline for almost any other instruction focused prompt. We also can implement an aspect-based prompt approach for the specific thought section to have an interchangeable prompt for different inputs. My best version of this is outlined in this dialogue summarization article.
Reasoning: Enable reasoning with either a generic instruction like "Thought can reason about the current situation" or a chain-of-thought prompt like "Let's think about this step by step”. This can be tied to a few shot prompting framework to provide the prompt exact examples of how to tie the reason to actions.
Actions: The last key information is the set of action commands from which the LLM can pick one in response to a reasoning thought. In the example above, "Search[entity]," "Lookup[keyword]," and "Finish[answer]" are action commands. Thanks to the few-shot examples we'll supply, the LLM knows to treat "entity," "keyword," and "answer" as placeholders to be suitably replaced at runtime.
A decent chunk of this stems from the idea that LLMs are really really really good at classification, specifically generating a single token that can be used as a “tag” with some provided context about what that tag means. We often use this system or a similar one in dynamic data chatbots where we can leverage (and want to leverage) some underlying knowledge to answer queries, but also incorporate dynamic data from APIs when required. We’re turning this prompt into a prompt system driven by a very high accuracy classification system at the front instead of a standard prompt instruction + goal state output definition system.
2. Supply Few-Shot Examples in the Prompt
Include a few task-specific in-context examples in the prompt to demonstrate the thought, action, and observation steps to the LLM.
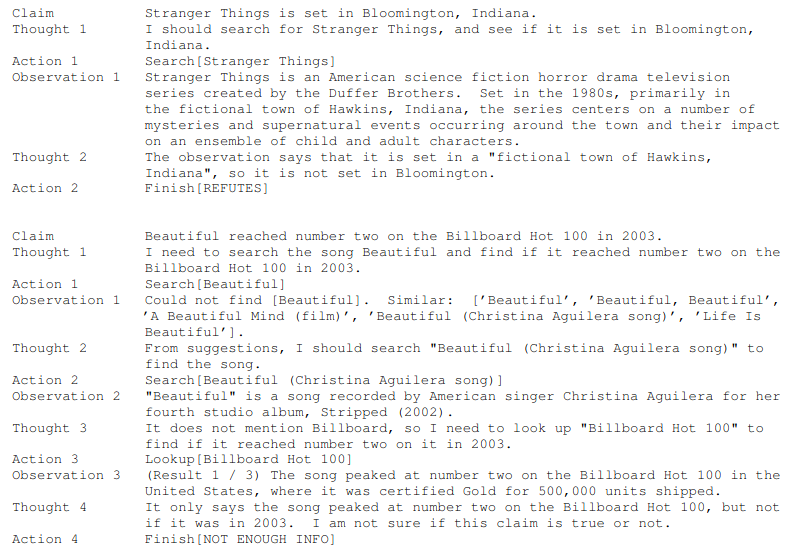
Some few-shot examples for a question-answering task are shown below:
Notice how the actions in the examples specify values like "Colorado orogeny" and "eastern sector" instead of the placeholders. This is how the LLM learns to replace the placeholders in the action commands with context-relevant values.
Some few-shot examples for a fact-checking task are shown below:
The optimum number of examples is task- and dataset-specific and must be determined experimentally. But you really need only a few. Even 3-6 are perfectly fine as we are just trying to define a goal state output definition, not add new knowledge to the model about the specific domain.
3. Consult Sources of Knowledge
Finally, you need to set up relevant sources of knowledge and application programming interfaces (APIs) that your application can consult in response to the action commands issued by the LLM.
These sources enable you to influence the LLM's reasoning and action planning using general information about the world or customer-specific information — information that can be very dynamic and volatile.
For example, in the example prompt above, when the LLM generates a "Search[entity]" action in response to a thought (with "entity" replaced by a context-specific value), the application queries the Wikipedia search API for that entity and returns the first few paragraphs of its Wikipedia page.
But it could just as well have fetched information from a constantly changing internal product and pricing database.
If the specified entity doesn't exist in that knowledge source, you can supply semantically similar values to make the LLM attack the task from different angles. This is shown in the example below:
We mostly use vector databases of knowledge here as they are easy to query with knowledge we’ve already extracted. We don’t have to deal with complex dynamic API calls to external services as we use our embedded vector generation service to retrieve the most relevant information based on the input task. This also works much better than systems we commonly see that query the database for any input (like chatbots) as we can use thought steps to make sure the context that is retrieved is actually relevant to the input and don’t ask the model to blindly use the information that comes back. This can cause disastrous results in use cases where the documents being stored in the vector database are all very semantically similar which leads to us pulling the wrong document. Imagine you have a database of just NDA clauses and the user puts in a very confusing input that semantically fits with the wrong clause. ReAct prompting can help to contextualize the input and what came back and understand if the context really fits.
In the following sections, we demonstrate these steps for several LLM-assisted business workflows.
Our ReAct Prompting System for Bank Customer Service Chatbots
Width.ai Banking Chatbot
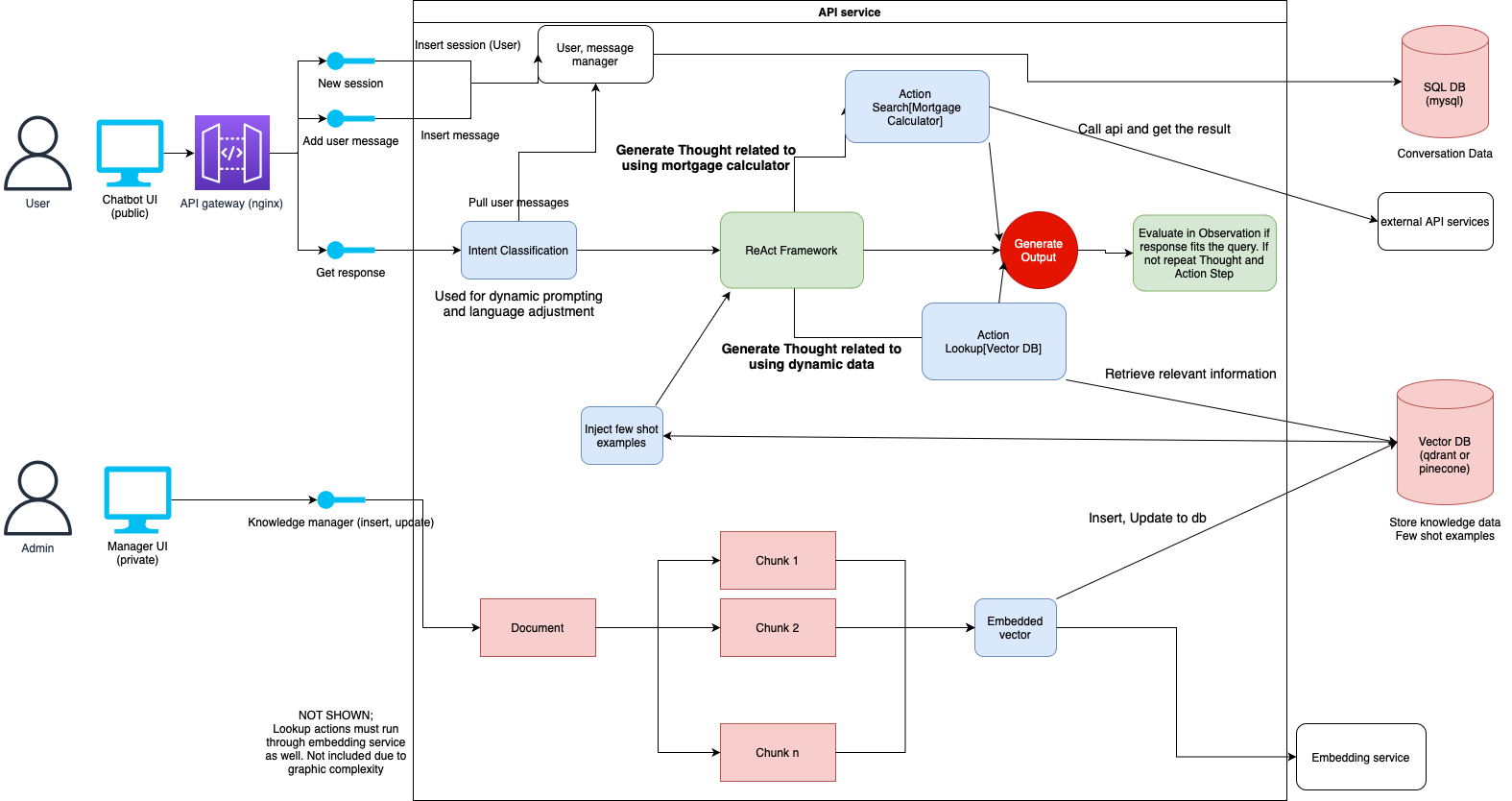
Our first pipeline takes a look at our chatbot framework that handles complex support and service inquiries from customers. Banking chatbots are a great example use case as they use a ton of external API services for things like mortgage calculators, and internal knowledge bases like customer databases. The user queries are also vague enough to make intent classification valuable.
How it works
Our chatbot framework uses a complex system of ReAct prompting, feedback loops, and external data sources to walk customers through their queries with a level of understanding about if the in-context information we’re using is relevant to reaching our final customer goal. One key step not mentioned due to graphic complexity is fine-tuned models for conversational response generation and embedded vector generation.
Intent Classification
We use intent classification in our more complex chatbots to allow us to dynamically prompt for different intents. This means that we can provide the models with different instructions and goal state outputs based on specific places the conversation should go. This greatly improves the accuracy as we can have task specific prompts that are less generic. We can fine-tune this model on entire conversations to take the entire conversation into account when generating intent.
ReAct Framework for response generation and context management
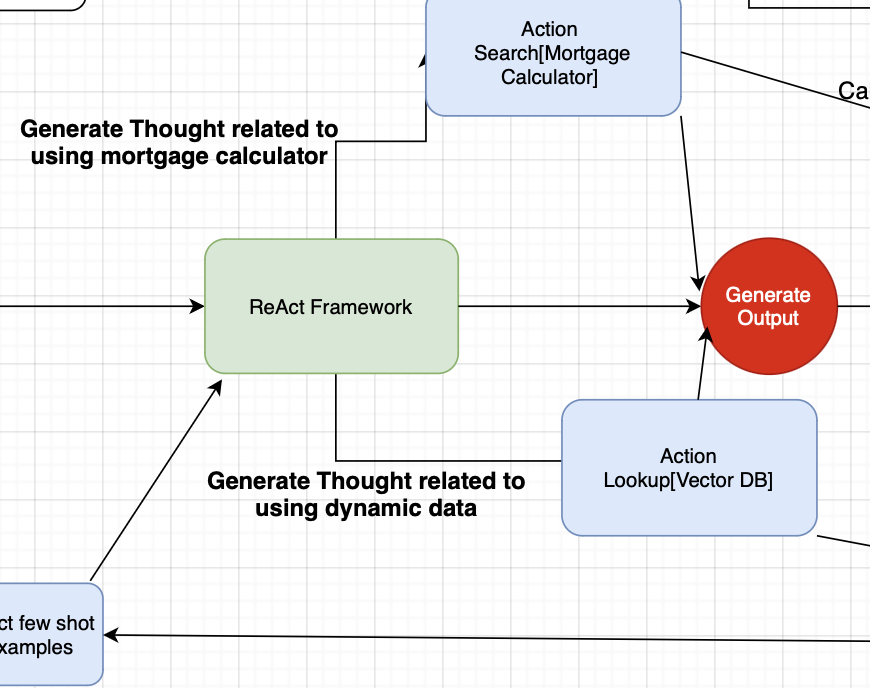
The ReAct framework on top of our LLM is the key driving factor behind guiding our conversation towards an end result that fits with the users intent. Our thought pipelines manage what actions we need to take to get relevant data and information based on the query or conversation up to this point. The thought pipelines are the most critical piece of the ReAct framework as they guide all the downstream tasks based on how we laid out the tasks required. We’ve trained a custom LLM on Thought generation to follow a specific format. The goal of the format is to outline all tasks required throughout the generation process upfront in a format that is easy to parse in multi-step conversations.
You can see we generate a Thought response that outlines the task in this format:
What you need to do right now
What happens when we get the data back OR what we generate. We don’t always call the dynamic functions, sometimes we just generate a response. This is a key feature of why we use this framework. Most chatbots do one or the other.
We outline what to do if the results don’t make sense. This being a part of the prompt helps the next Thought generations.
The Action step runs the process of extracting data from our sources. We generate a tag that is used to kick this off with code. In the banking chatbot this means either external API services or a database lookup. The action step acts as an in-context classifier for understanding where we need to pull data from. More complex versions of this operate a bit more like ToolFormer by generating a response with keys used to fill in dynamic data. This lets us generate the response and pull in the required dynamic data in the same step.
This ToolFormer example does a great job of showing how we can generate a response to the query with dynamic tags for lookup.
The Action step is also used for deciding if we’ve reached a correct result to return to the user. We generate a tag with something like Finish[Output] when the framework believes the results are correct. We can also use this Action step to decide if we need to loop back through with different information or restart the process due to an error.
Observation is used to generate our response to the user, or repeat the process from step one if the Action step was unsuccessful. Some systems will just skip the Observation step if the Action step fails, while others will provide output that can be used by the next loop for understanding of what failed before. This is a key step as well given it evaluates everything we’ve done to this point and makes critical decisions around the path we take forward. Whether we return the result or not to the user, this step guides what changes we make for the next run if required. In automated systems the observation step can be used to automatically run downstream tasks as well in a Plan & Execute framework.
External API Services & Vector DB
Our dynamic data is accessible through two different sources. External API services focus on connecting to data APIs that require an API call, either existing workflow tools like Mortgage calculators or managed services like Textract for data processing. These have different API setups for each tool which requires us to build API connectors from our Action step outputs to the API format for each tool. Newer systems can leverage the OpenAi Code Functions system to make this connector a bit cleaner.
The Vector DB lookup is a bit cleaner as we just have to provide a text query. Many simple chatbots we see that have issues just pass the exact user query to the Vector DB and try to return the best results. The problem with this is that a single user query is oftentimes a poor representation of the entire task the user is trying to perform. Imagine a user's initial query is “how do I open an account?” and we pull back high level information about how to do that. Then we ask “where are you located?” as the account process is different for different countries. The problem we have is that the query the user just provided isn’t relevant to the account opening process by itself. We clean this up by using our custom query generation model, which takes the entire conversation into account and creates a new query that focuses on the most recent queries, but pulls context from previous queries that is needed for a lookup. This makes it much easier to have multi-step conversations that require lookups throughout the conversation for needed context.
Embedded Vector Generation
Embedded vectors are used in two key spots in our pipeline, one is online and one is offline.
Embedded vector generation of non-dynamic data. This is the data that is uploaded and stored in the vector DB to be extracted during our Lookup[] actions. As documents are uploaded we perform an offline process of extracting text, structuring into a specific format, and generating embedded vectors.
Runtime queries that are used to extract information from our Vector DB must be transformed into an embedded vector. This is a real time process that is performed after our query generation model creates the text string.
We’ve built a product (currently in private beta for our customers) that customizes our embedded vector generation model for better information retrieval. The goal of this customization is to improve the models understanding of what information in the database is semantically similar to queries. Oftentimes these large Vector DBs have a ton of data that overlaps or is extremely similar which can make it complicated to pull the exact relevant document we need for a query, especially if the query is a bit more vague or not aligned with the users end goal. This custom model better understands the relationship between query style inputs and document style chunks and has a new understanding of “similar”.
What Business Problems Is ReAct Addressing?
The ReAct approach can address some problems that are typical in such use cases:
Handle complex queries: In banking and finance, the inherent complexity of the industry sees many customers asking complex questions with a lot of personal details and unique conditions. A good human executive would have to work through a complex decision tree to provide suitable choices to customers. ReAct can simulate that behavior to some extent. Use cases like account sign up and management often require multiple steps and questions, which is why they have been very human heavy in the past. Our connection to non-dynamic documents and external APIs allows us to interact with all the steps required to complete these processes.
Provide customer-specific answers: Since ReAct integrates sources of knowledge into its reasoning and action plans, you can arrange to provide customer-specific details to the chatbot for highly personalized answers.
Reduce customer frustration: Related to the above, most current chatbots can't handle even moderately complex queries. Plus, many automated and human assistants fail to even pay attention to all the details a customer provides. This often leads to customer frustration and loss of business. Approaches like ReAct can ameliorate such complex-query issues.
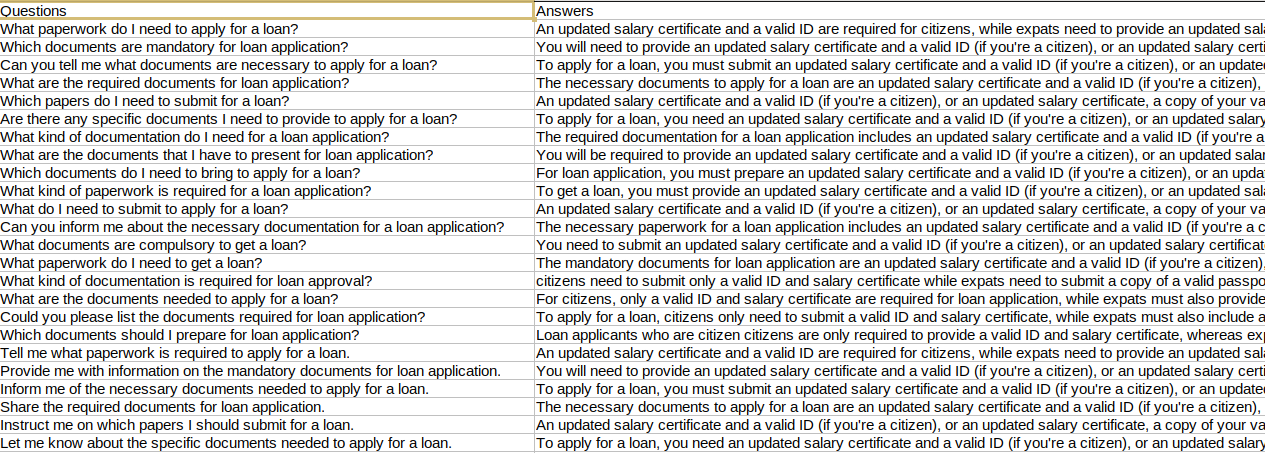
Handling Complex Customer Queries Using Few Shot Examples
You'll typically have an existing set of customer service workflows and frequently asked questions (FAQs) that human executives walk a customer through. We can use these as few shot examples that are stored in the Vector DB alongside the non-dynamic data and pull them into the prompt.
The FAQs contain scripted answers to simple generic questions.
The workflows will be a set of conditions to check and questions to ask (typically based on the FAQs) or actions to perform.
Typical customer FAQ
A ReAct implementation has the same structure and components as explained earlier. But you must pay attention to certain information:
Few-shot examples: Your examples must demonstrate thought, action, and observation steps for complex queries. A complex query consists of multiple constituent questions. The answer to a complex query must cohesively combine all the answers to those questions, and in addition, personalize it with product, service, and customer-specific details like customized offers or discounts.
Sources of knowledge: Your configured actions must enable you to fetch relevant generic answers and customer-specific details from your FAQs and databases.
ECommerce Product Search Using ReAct Prompting
Another use case that benefits from the ReAct framework approach is ecommerce product search. Some of the constraints that have made large scale ecommerce chatbots difficult in the past are why ReAct works so well for this use case:
Thousands of products - The vector DB approach and Observation step to check our work makes it extremely easy to manage these products. We’ve scaled this up to over 3.2 million products and can handle large product data formats like technical spec sheets.
Example of a technical spec sheet we would ingest for product data to use in the chatbot. (full PDF source)
A large set of characteristics and lots of product variations along those characteristics - This is one of the key issues I see when larger catalogs are trying to build chatbots. These products have incredibly detailed descriptions, and can have a ton of different SKUs that differ on small things like voltage, size, make etc. Products can be exactly the same and just have different manufacturers for OEM etc.
Constantly changing details like availability, pricing, and offers - This is where the dynamic data API comes into play. ReActs ability to manage both the vector DB and external APIs and understand when to use which one is key to make sure we pull in product data and the required dynamic data associated with that specific product is critical.
Understanding images - Through embedded vectors we can leverage the images provided for an even better understanding of the product data. We have one of the highest accuracy image matching tools, and have outperformed the base CLIP model (case study).
What ECommerce Frustrations Can ReAct Address?
The e-commerce shopping experience has remained largely unchanged over the last quarter century. Most of these problems are related to the user experience that often fails to satisfy the product need(s) a buyer has in mind. Typical problems include:
Difficulty searching products that satisfy multiple criteria: Most buyers have a complex set of criteria in their minds related to appearance, colors, pricing, texture, and so on. While search checkboxes help with some of these needs, manipulating a dozen checkboxes as a way of expressing your criteria is a tiring, suboptimal experience. A better interface would accept all the primary criteria upfront in natural language, shortlist only perfectly matching products, and then allow the buyer to incrementally refine their choices.
Difficulties in buying multiple products that satisfy collective criteria: Even more frustrating is the shopping experience of buying multiple products that satisfy collective criteria on the net price or shipping date. Most e-commerce search experiences just aren't built for it.
ReAct provides solutions to overcome these difficulties. Below is an example of a complex product query:
Here's how a ReAct LLM reasons and processes the query step by step to satisfy all the criteria:
1. Search the Product Database for the Main Query
First, the main query is passed to the product database to return all products that naively match the query using either semantic or keyword search:
Initial search for all candidate products (Source: Yao et al.)
2. Examine Each Product More Closely Using Reasoning
The initial search yielded results based on semantic or keyword similarity. In this step, the LLM examines each product using reasoning to eliminate any that don't actually match the user's product need. For example:
The LLM's reasoning step showed that none of the first set of candidates are good matches. It discarded two of them completely but elected to examine the third more deeply.
Examining possible candidates and product variants (Source: Yao et al.)
On closer examination of the product, it discovered that the product has multiple flavors including the user's preferred flavor of apple cinnamon.
3. Verify the Remaining Criteria
The user had also specified quantity and pricing criteria. The LLM verified that the product satisfied them. It proceeded to buy the product on behalf of the user in this example, but it could also have displayed that shortlisted product and left it to the user for further evaluation.
How to Implement E-Commerce Product Search Using ReAct Prompting
For this use case too, the few-shot examples and the sources of product knowledge are crucial. The few-shot examples with thought, action, and observation steps look like this:
Better Medical Summarization Using ReAct Prompting
For this use case, we move away from short-form content examples toward long-form document understanding. In health care, sitting down with your customers (patients) and explaining everything in detail helps build trust. However, due to systemic problems like overworked staff and staff shortages, health care professionals don't have the luxury of being able to show attention or patience to each person in their care.
This combination of the need for long-form document understanding under severe time constraints is also observed in other organizations like:
Research
Public-facing government offices
The judicial system
The immigration system
The welfare system
Certain financial services like loans
Court judgments often refer to other cases. Research papers typically cite other research papers. All these relationships must be considered as relevant information when using LLMs for summarization or question-answering tasks.
What Health Care Problems Can ReAct Address?
ReAct-capable LLM workflows can potentially alleviate these common problems. LLMs are naturally good at explaining long-form documents at any comprehension level in most popular languages.
Unfortunately, LLMs by themselves are not good at combining relevant information from multiple sources. For example, to patiently explain a medical report to a patient and answer all their layperson questions, an LLM-based chatbot may need access to general health, anatomy, and physiology knowledge too.
ReAct can address those drawbacks thanks to its reasoning and action planning based on sources of knowledge.
How to Implement ReAct in Health Care
We've already seen how generic sources of health information like Wikipedia can be integrated. But you aren't restricted on the number of knowledge sources you can integrate with ReAct. Each action can consult multiple sources and select the best information.
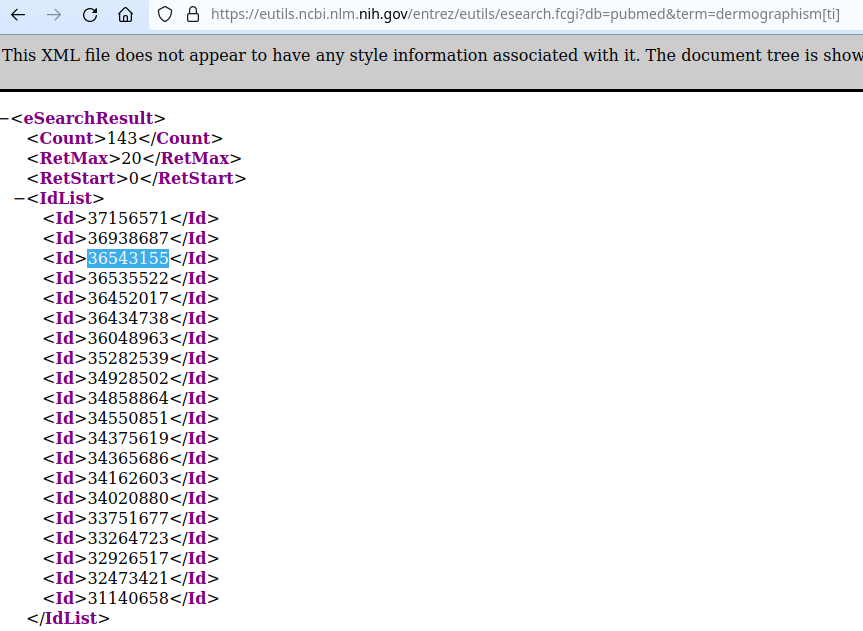
One set of reliable health information is the PubMed database of peer-reviewed and published medical articles from popular journals.
PubMed's e-utilities API provides text search and article fetching. Your ReAct implementation can generate appropriate commands for your application to consult PubMed's database and return information relevant to the thought, action, and observation steps of the LLM.
Example
Take this medical report as an example:
The average layperson won't understand terms like aquagenic urticaria or dermographism. That kind of jargon is common in health reports and frustrates the ability of patients to act in the best interests of their long-term health care.
To solve this issue:
Few-shot examples: Design your few-shot examples to issue an action command whenever the LLM encounters any unfamiliar jargon.
PubMed integration: On receiving the command, use the PubMed e-utilities APIs to look up that jargon, download relevant articles, and summarize them.
For example, the PubMed term search API returns these results:
The IDs above are PubMed document IDs.
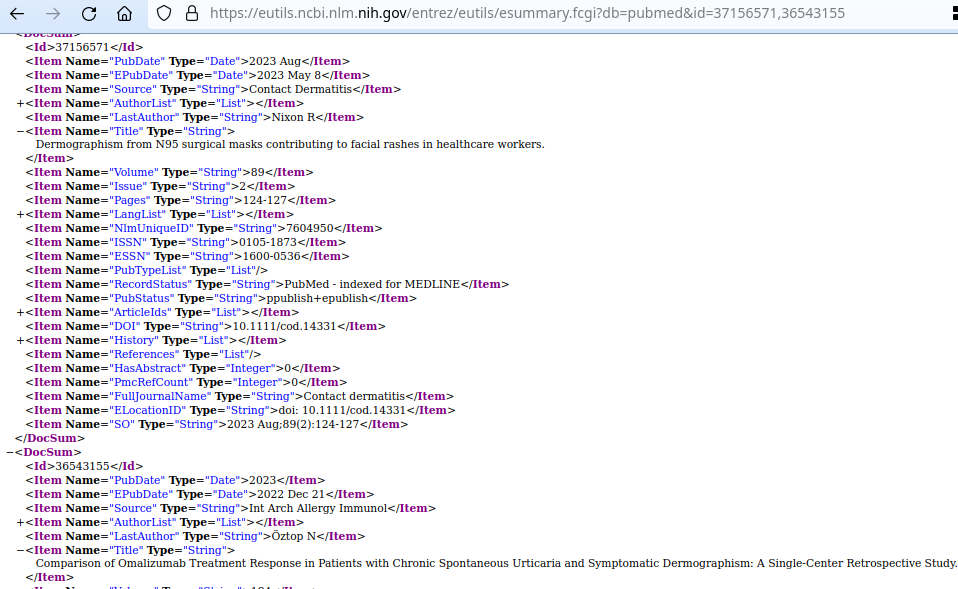
Your application can obtain summaries of those document IDs using the PubMed summary API:
These summaries are the observations for the LLM's subsequent reasoning steps. An LLM integrates this PubMed information into its summaries or chatbot answers.
ReAct vs. OpenAI Function-Calling
If you're using OpenAI LLMs like GPT-4, you can implement ReAct more cleanly using its function-calling capability. The differences between what we've demonstrated so far and OpenAI APIs are explained below.
Structured Action Specification
In standard ReAct, the action commands are rather unstructured. You list them in the prompt with some instructions on when to output which command. The information to a command is specified using placeholders. But the concept of placeholders must be demonstrated to the LLM through your few-shot examples.
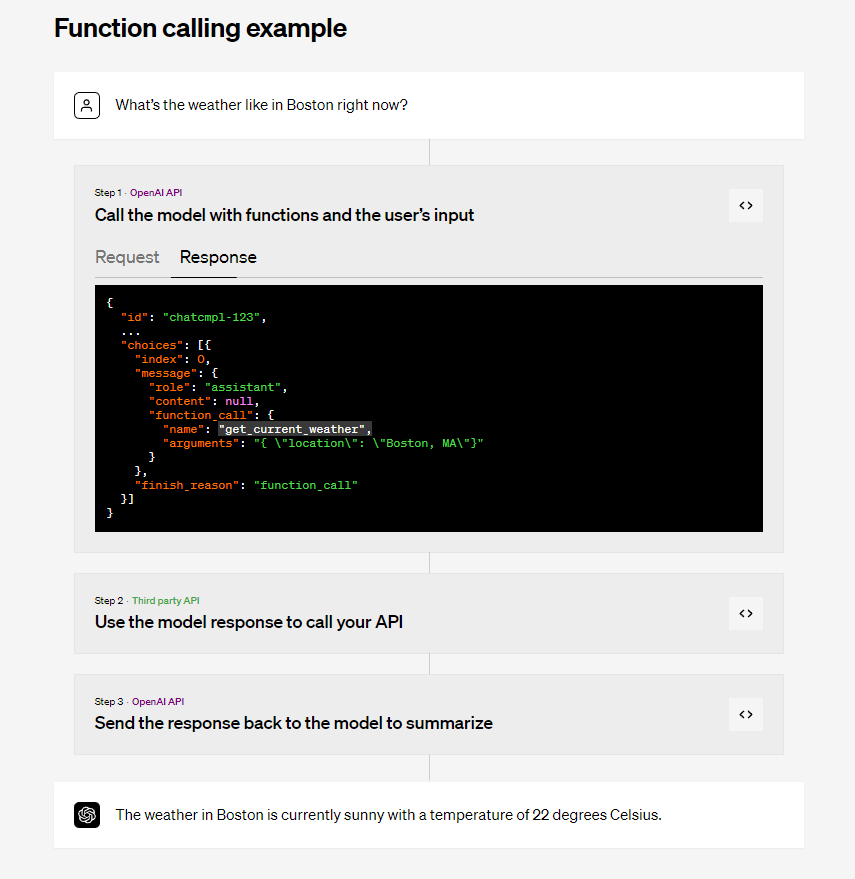
In contrast, OpenAI's API enables you to specify actions and their information in great detail as shown below:
OpenAI function calling API example (Source: OpenAI)
The LLM uses all that information and metadata — the function description, parameter property descriptions, parameter units, and so on — to make more informed decisions on when to invoke your actions.
Structured Action Invocation
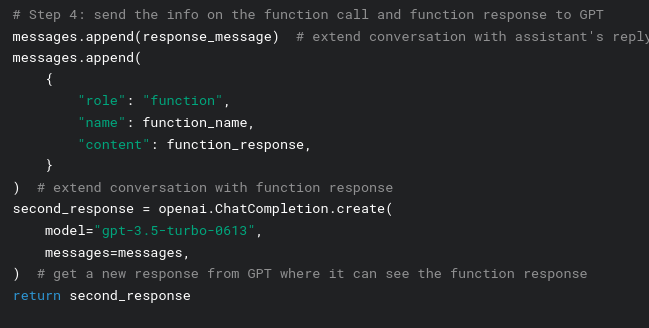
The action invocation too is far more structured with OpenAI API. With standard ReAct, actions must be detected by parsing the LLM's results. When you detect an action command, you execute it. Its result must be appended to the prompt by your application.
In contrast, OpenAI allows structured invocation of actions and transmission of your action responses back to the LLM:
In summary, if you're using OpenAI APIs, implement ReAct using function-calling.
Managing Context Length Restrictions
A quick implementation note on managing token lengths is in order because you'll face it often in ReAct implementations. Any observation in the ReAct approach typically pulls in fairly long content, be it a Wikipedia article or a PubMed paper. When combined with few-shot examples, the prompts can get lengthy and overflow context length restrictions.
How should you address this problem? There are a couple of approaches:
Chunking: Combine the ReAct steps with some kind of chunking to divide knowledge content into smaller pieces and reason separately on each piece. The chunking strategy can naively divide content into equal pieces with some overlaps. Alternatively, you can use sophisticated chunking based on semantic similarities and relevance.
Partial content: Another common approach is to just use a part of the observation that's likely to be under the context length restrictions of the LLM.
Using ReAct Prompting for Human-Like Reasoning and Action Planning
In this article, you saw how ReAct prompting enables LLMs to replicate human-like reasoning and action planning. It can potentially streamline many of your LLM-assisted use cases that involve reasoning and humans in the loop. Contact us to help you improve your workflows using LLMs.
References
Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik Narasimhan, Yuan Cao (2022). "ReAct: Synergizing Reasoning and Acting in Language Models." arXiv:2210.03629 [cs.CL]. https://arxiv.org/abs/2210.03629