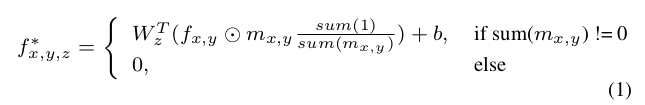Recurrent feature reasoning output on the right vs. reconstruction of visual structure in the middle (Source: Li et al.)
Does your business routinely remove, redact, or censor information from images and videos for business or legal reasons? Perhaps you redact people's names or photos from all your scanned documents for privacy reasons? Or censor competitors' products from your marketing videos? Or maybe you run a tourism site that gets thousands of image uploads from your users, and you want to give them a way to remove unwanted people and objects from their photos.
All these workflows can benefit from a computer vision task called image inpainting. In this article, you'll learn what image inpainting is, what it's used for, and how to implement it using a technique called recurrent feature reasoning for image inpainting.
What Is Image Inpainting? What Can You Do With It?
Image inpainting fills in any holes or gaps in an image with artificially generated patches that seem visually and semantically coherent with the rest of the image to an observer. The holes may arise due to deliberate editing to remove unwanted people or objects from images, or as a result of damage to old photographs and paintings over time.
Some use cases of image inpainting:
Replace unwanted persons or objects in photos: After you edit out an unwanted object or person from a photo, use inpainting to fill in the hole with a visually consistent background or set of objects.
Combine segmentation and inpainting for automated image editing: If you have a large number of photos that require mundane editing or censoring but you’re currently doing this manually, you can automate the workflow by using text-guided segmentation to automatically select the objects you want to remove and then replacing them using inpainting.
Generate product photos: For your marketing and sales campaigns, you can generate new natural-looking backgrounds around your product photos.
Create stock images and illustrations for your blogs and websites: Inpainting is an efficient way to generate free novel stock images and illustrations that aren't encumbered by copyright or licensing restrictions, and that can be freely used on your blog, on your website, or in your online store.
Restore damaged photos and videos: If your business handles old, damaged photos, you can scan them to a digital image format and restore their damaged areas using inpainting. You can do the same for old videos on older storage media like videotapes that may be damaged or corrupted.
In the next section, we'll dive into one of the deep learning-based image inpainting methods, called recurrent feature reasoning.
Recurrent Feature Reasoning for Image Inpainting
Recurrent feature reasoning (RFR) is a progressive inpainting approach, proposed by Li et al. in 2020, to overcome the problems of prior traditional and deep learning approaches. The word "recurrent" here refers to refining the quality of inpainting over many steps and using the previous step's output for each subsequent step.
The proposed network model, RFR-Net, uses only convolutional and attention layers, not any standard recurrent layers. Also, RFR-Net is not a generative adversarial network like many other inpainting models; it has no discriminator network and doesn't use adversarial training.
Intuition and Benefits of Recurrent Feature Reasoning
Inpainting in the feature space starting from hole boundaries and moving toward the center (Source: Li et al.)
The main intuition behind RFR is that it progressively replaces the regions of a hole with high-quality visual information, starting from the boundary areas of the hole and incrementally moving in toward the center.
The other important aspect to know is that its inpainting is done on the features derived from pixels and not directly on the pixels. These features include intuitive ones like hues, intensities, textures, contours, or shapes. But they also include less intuitive, nonlinear features that are abstract mathematical combinations of simpler features but that help to faithfully generate the visual aspects seen in real images.
The benefits of RFR include:
More high-quality information for inpainting: The feature space decomposes an image into its constituent visual aspects like textures and contours. This provides far more information and at the same time, allows an inpainting algorithm to be far more fine-grained than one that works directly on the pixels.
Recurrent feature reasoning outperforms other models on popular datasets like CelebA and Paris StreetView in noisy and difficult images.
Better at large continuous hole filling: At this point in generative ai many methods of image inpainting are good at fixing small image defects and closed off holes. Larger continuous holes such as the ones above are what give most existing image inpainting methods trouble. As we’ll see below, RFR outperforms these other methods in this domain.
More efficient than other image inpainting methods: Remaining in the feature space until the very end is more efficient and less lossy than other techniques that keep flitting between the feature and pixel spaces. RFR takes between 85-95 ms at inference time to generate images which is faster than several of the SOTA methods.
Recurrent model reuses information: Its recurrent design enables the model to reuse information from previous iterations and to remain lightweight.
Flexible computational cost: RFR's recurrent operations are portable. They can be moved up or down the stack of any network and can also be easily expanded or reduced depending on the available hardware and time constraints.
Demo and Examples
The panel below shows inpainting with recurrent feature reasoning in action, with the hole getting filled incrementally.
In this section, we'll explain the logic of recurrent feature reasoning. Just remember that whenever we use the term "inpainting" here, it's referring to the image inpainting on the feature maps extracted by convolutional layers and not directly on the image pixels themselves. The final image is generated only at the end from the inpainted feature maps.
RFR's inpainting refines the feature maps by running these two steps in sequence multiple times (six by default, but you can customize it to your data):
1. Identify the target area for inpainting: Starting from the hole's boundaries in the current iteration, identify the next set of regions near the boundary to inpaint. Any area with at least one unmasked pixel is included, while areas with only masked pixels are excluded. This is similar to the mask-awareness concept.
2. Feature reasoning: Paint high-quality features for the identified areas using a standard set of encoder and decoder convolutional layers, with a special attention layer included for long-range dependencies.
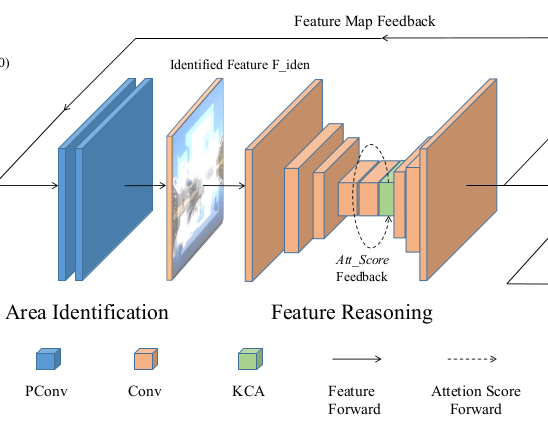
At a high level, the RFR module recurrently infers the image hole outer boundaries of the convolutional feature maps and then uses those same feature maps as “clues” for further inference.
Target Area Identification Step
RFR progressively fills in holes, starting from their boundaries and moving inwards. At each step, it must identify the boundary patches with at least a few useful features that it can use for the inpainting.
It does this by building new feature maps using partial convolutions, first proposed by Liu et al. Unlike standard convolution, a partial convolution first multiplies a feature patch and the corresponding region of the mask, then applies the convolution to their product, and finally normalizes the result using the sum of valid masked values under that patch.
This is followed by a mask update step where that region of the mask is marked as completely valid for subsequent convolutions and iterations.
RFR-Net uses many such partial convolutional layers to update both the feature maps and the masks. The feature maps are then passed through a normalization layer and a nonlinear activation like a rectified linear unit to prepare them for the next step.
The difference between the updated mask and the input mask is the target area identified for inpainting.
Feature Reasoning Step
Recurrent feature reasoning steps (Source: Li et al.)
This step generates high-quality feature maps for the identified target area using a stack of regular convolutional encoders and decoders with skip connections. The intuition here is that during training, these convolutional weights acquire values such that the generated feature maps are tuned to the visual aspects and other patterns — colors, textures, contours, shapes, sizes, and more — prevalent in the training images.
Knowledge-Consistent Attention for Long-Range Influence
The recurrent feature reasoning module also includes a special attention layer called the knowledge-consistent attention (KCA) layer. As you probably know, a major weakness of convolutional layers is their inability to model the influence of more distant regions on an area. Distant regions can influence an area only when a layer's receptive field becomes large enough to include them. But even then, the quality is compromised by the pooling layers that discard a lot of useful information about the distant influence.
Attention mechanisms overcome this weakness by modeling the influence of every feature on every other feature at every layer. So even a standard attention layer can improve the quality of features generated within an iteration. However, though it improves the features in each iteration, it doesn't work well overall specifically for RFR-Net.
That's because the attention scores are independently calculated in each iteration. If we select two random locations, they may have a high attention score in one iteration but score very low in the next, due to some side effects of the feature reasoning and mask update steps. Such inter-iteration inconsistency results in odd effects like missing pixels or blurs.
Knowledge-consistent attention scores (Source: Li et al.)
To overcome this, the KCA layer caches attention maps from the previous iteration and uses a weighted sum of the current attention scores and the previous iteration's scores. This ensures that all knowledge about current features is passed down to the next iteration too, making the feature maps consistent with one another across any number of iterations. The weights of the weighted sum are learnable parameters that are inferred during training.
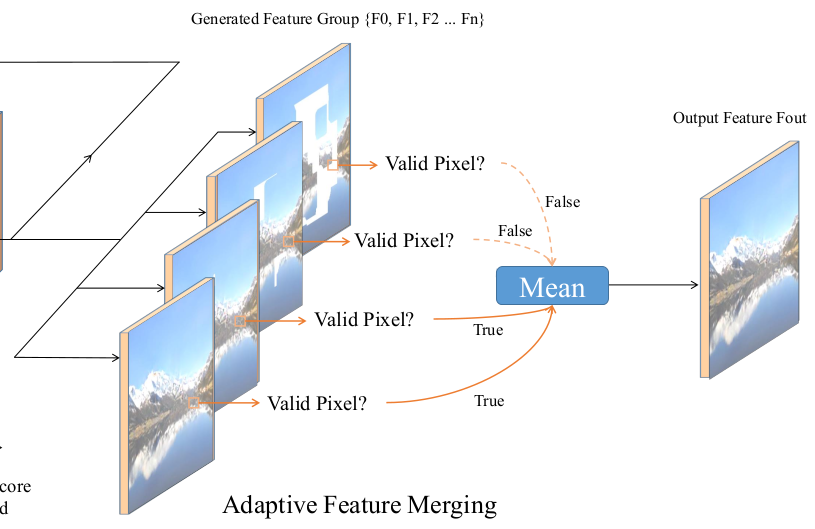
Adaptive Feature Merging
Adaptive feature merging stage (Source: Li et al.)
The last stage of RFR-Net is creating the final image from the inpainted feature maps generated during the multiple iterations. Each iteration creates inpainted feature maps that fill more holes than the previous iteration. However, if you use just the final inpainted feature maps and discard all the earlier ones, you lose a lot of useful intermediate features.
Instead, RFR-Net prefers to consider all intermediate feature maps for a location that has some unmasked details. It averages them to calculate the final inpainted feature maps.
To these final inpainted feature maps, a convolution is applied to calculate the pixels that make up the final image.
Training RFR-Net
The GitHub project for the RFR-Net paper provides links to two RFR-Net models pre-trained on the CelebA and Paris StreetView datasets. These are suitable for inpainting on faces and buildings respectively.
But if you want to inpaint on other types of images, should you train a custom RFR-Net model? The small size of the model works better for domain-specific training images with less to medium diversity rather than a general model capable of inpainting on any kind of image.
Loss Functions
The loss function used for training RFR-Net is a combination of four losses:
Perceptual loss: A VGG16 feature extractor extracts features from the ground truth and generated images. The sum of the differences between their features from all the pooling layers is their perceptual loss.
Style loss: This too uses the same pooling layers' feature maps to calculate a style score per pooling layer. The sum of the differences between style scores from all the pooling layers is the style loss.
Unmasked area difference: This is the absolute (L1) difference between the unmasked areas of the generated image and the ground truth image.
Masked area difference: This is the absolute (L1) difference between the masked areas of the generated image and the ground truth image.
Training Procedure
You can make the training completely self-supervised since the images you collect serve as both ground truth images and training images. After collecting your training images, add a custom transform to the PyTorch data loader to draw random masks and streaks over the images.
Execute run.py to train a custom model from scratch or to fine-tune an existing one. The masks must be 8-bit grayscale images with black (zero) for unmasked areas and white (255) for masked areas.
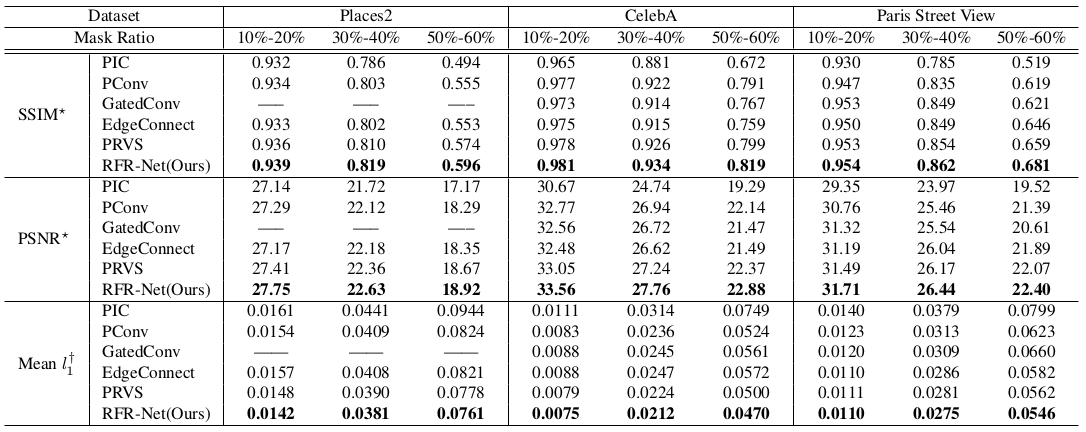
Evaluation and Metrics
Qualitative comparisons with other inpainting models (Source: Li et al.)
The metrics used for quantitative evaluation were:
Structural similarity index measure (SSIM): The SSIM metric calculates the perceptual quality of the generated image by measuring the structure (spatial patterns), luminance, and contrast.
Peak signal-to-noise ratio: It's another perceptual metric based on maximum intensity and mean squared error between two images.
Mean L1 loss: This is the mean of absolute differences between the generated and reference images.
Quantitative comparison with other inpainting models on key metrics (Source: Li et al.)
RFR-Net scores better than many other convolutional deep models on all the metrics at different masking ratios!
Recurrent Feature Reasoning vs. Stable Diffusion and DALL-E 2
Stable diffusion (SD) and DALL-E 2 are currently very popular for inpainting. Here are some aspects to consider when evaluating them against recurrent feature reasoning for your use cases.
Both SD and DALL-E 2 inpainting are guided by instructions you give in natural language. They tend to generate images that are creative by misunderstanding the meaning of your instructions and also because they've been trained on large datasets that may match the instructions in multiple ways. You may find unexpected objects or styles included in the generated image. Getting to your desired image may require several rounds of prompting and editing. For some use cases, like blog image generation, that may be acceptable.
But for more straightforward business use cases, like product image generation, you may prefer the realism of RFR. Since it's a small model, it only generates images that are close to what it saw while training.
2. General vs. Domain-Specific Image Inpainting
Both DALL-E 2 and SD are large models that are trained on large and diverse image and language datasets. They're capable of general inpainting on any type of image.
In contrast, RFR is a small model that works best when trained on domain-specific datasets that are quite homogeneous with less diversity in the classes. For example, if you want to generate images of women's garments for your online store, train it only on women's garments without including any other classes or even images of other clothes.
3. Deployment Options and Restrictions
DALL-E 2 is available as a web application for human use and via an application programming interface (API) for automation. However, its model and weights are not available to you for deployment on your infrastructure. Other restrictions include:
API quotas limit the number of API calls you can make.
Image file sizes have to be below 4MB, which is fine for JPEGs but unsuitable for other formats like PNG or TIFF.
All calls are metered and paid.
In contrast, you can deploy SD and RFR on your server or even your laptop. SD can run on consumer GPUs with about 10GB of video memory, and some of its optimized clones require even less. Meanwhile, RFR's paper used a medium-configuration machine from 2020 with i7-6800K and 11G RTX2080Ti GPU. RFR is small enough to optimize and run even on modern smartphones.
4. Performance Differences
All three are fine for near-real-time generation and generate images for any resolution within milliseconds. However, end-to-end time consumption may be quite different. As stated earlier, both SD and DALL-E 2 can get quite creative and may require multiple rounds of editing and prompting. In contrast, RFR just generates images quite close to what it saw during training and requires less editing time.
DALL-E 2 is a diffusion model, while Stable Diffusion is a latent diffusion model. Diffusion is a type of denoising that progressively removes noise to guide an image from a noisy start to the user's desired image. SD's latent diffusion just means that it does the denoising in a latent space rather than directly on images. Both are text-guided, and text is a fundamental constituent of their inputs.
RFR is a vision-only convolutional network. The two aspects that are slightly different about it are a specialized attention layer and partial convolutions.
An Easy Approach to Image Inpainting
The recurrent feature reasoning approach is a simple and intuitive technique, and at the same time, effective and efficient. The model's size and computational simplicity allow it to be ported to smartphones where automated image editing and inpainting have many more potential uses, including speech-guided editing. Contact us to learn more about the many products we've already built with image inpainting and outpainting for things like marketing image generation, product image generation, and more!
References
Jingyuan Li, Ning Wang, Lefei Zhang, Bo Du, Dacheng Tao (2020). “Recurrent Feature Reasoning for Image Inpainting.” arXiv:2008.03737 [cs.CV].https://arxiv.org/abs/2008.03737
Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, Björn Ommer (2021). "High-Resolution Image Synthesis with Latent Diffusion Models". arXiv:2112.10752 [cs.CV]. https://arxiv.org/abs/2112.10752