Many businesses have to frequently identify, count, and track things on their premises. Retail is an obvious example, but others like logistics, remote sensing, and autonomous vehicles also have similar needs. Segmentation is a critical computer vision task used for such problems. In this article, learn about semantic segmentation vs. instance segmentation, their uses, and modern approaches.
What Is Segmentation?
Object detection (left) is limited to bounding boxes. Instance segmentation (right) is more fine-grained and traces contours (Original photo by Franki Chamaki on Unsplash)
Segmentation is the computer vision task of identifying and locating an object (or objects) in an image by dividing it into irregularly shaped regions, called segments, that correspond to the shapes of different objects or parts of the scene.
It's similar to object detection, but while detection is satisfied with rectangular bounding boxes around objects, segmentation traces out the contours of objects at a pixel level.
There are many segmentation tasks depending on the nature of your input and the information you want out of them.
Semantic Segmentation vs. Instance Segmentation vs. Panoptic Segmentation
Based on their core functionality, the three types of segmentation are semantic, instance, and panoptic.
Semantic segmentation is only interested in the classes of objects, not individual objects. Each segment corresponds to one class covering the objects of that class, even if they're far apart in the scene. It assigns a class label to each pixel and uses the same class label for the pixels of any object of that class. Each segment is output as an image-sized overlay mask covering all the pixels of that class.
Instance or object segmentation not only identifies the classes but also differentiates each object within a class. Each segment corresponds to an individual object instance. It assigns both a class label and a unique object identifier to each pixel. Uncountable background elements, like the sky or the ground, are usually ignored.
Panoptic segmentation just combines semantic and instance segmentation. Like instance segmentation, it differentiates each object within a class. Like semantic segmentation, it labels the background elements, too.
Other Segmentation Methods
One-shot (visual prompt) and referring (text prompt) segmentation (Source: Lüddecke and Ecker)
Based on the nature of their inputs, other types of segmentation tasks are:
Referring or text-guided segmentation: It takes a text description as additional input and segments the objects or background that match that description. If the description is from a fixed set learned during training, it's called closed-set segmentation. But if it's any arbitrary text, it's called open-set or open-vocabulary.
Zero-shot segmentation: Normally, only the classes seen during training are segmented. But zero-shot segmentation's goal is to segment even unseen new classes without retraining a model. It does this by relating the unseen classes to known classes.
One-shot segmentation: One-shot segmentation is a type of zero-shot segmentation where each unseen class is provided via an example image. It relates the example image to known classes based on visual similarities.
Video segmentation: Segmentation normally works on images. But when the input is a video, it's called video segmentation. Since we don't think of an object in one frame as different from the same object in the next frame, video segmentation must not only segment objects but also track them with the same identifiers between frames.
Uses of Semantic Segmentation vs. Instance Segmentation
Let's see how segmentation is applied in some verticals.
Health Care
Organ segmentation on human MRI images (Source: Chen et al.)
Segmentation is frequently used in medical and biological research to isolate organisms, cells, tumors, or other areas of interest. For example:
The highly irregular shapes of natural elements make segmentation an indispensable tool in remote sensing and its applied areas like agriculture. Segmentation is used for purposes like:
Crop mapping on hyperspectral images from drones by using a spectral-feature attention module added to a TransUNet model to aggregate spectral features
Accurate crop segmentation by fusing local features from a CNN and global features from a CSwin transformer that implements cross-shaped shifted windows
Mapping changes in rivers and other geological features
In the next section, you'll find out the modern approaches being used for segmentation.
Modern Deep Learning Approaches to Semantic Segmentation vs. Instance Segmentation
Transformers and convolutional neural networks (CNNs) are the two broad approaches to modern segmentation. CNNs, like U-Net and the fully convolutional network for semantic segmentation and mask R-CNN for instance segmentation, remain popular. But a big problem with CNNs is their limited ability to model long-range and global relationships between distant parts of an image. They can't do it until the receptive field is large enough, and even then, pooling discards a lot of useful information. Transformers surpass them by using multi-head self-attention in every layer.
Recent innovations in CNNs like ConvNeXT improve on this weakness using ideas like group-wise and depth-wise convolutions that behave like self-attention. Some new segmentation models have started using ConvNeXT as their backbone network.
Unlike CNNs, transformers are not limited to operating on local grids. Their ability to combine irregular regions from nearby and distant parts of the image, using self-attention at every layer, makes them powerful segmenters. In this article, we'll focus on transformer-based segmentation to bring you insights into this new area that's rather under the radar.
Architectural Patterns in Transformer-Based Segmentation
What architectural traits do we see in transformer approaches to segmentation?
First, the vision transformer (ViT) or its improved variants are the most common backbone networks. The improved variants include the following:
Swin transformer: Its shifted windows concept makes it similar to convolutions, allowing transformer blocks to form a hierarchical pyramid.
Hybrid networks with convolutional blocks: While transformers can take in more context, they are computationally less efficient due to the quadratic complexity of self-attention. Many variants add convolutional capabilities to make transformers more efficient. They include the convolutional vision transformer, co-scale, and LeViT.
Improved spatial self-attention: The twins models improve both accuracy and efficiency by optimizing spatial self-attention aspects.
A second trait is the use of different encoder-decoder architectures:
Transformer for both encoder and decoder: One such transformer-only model is the segmenter that adapts ViT for semantic segmentation.
Image-text encoder with transformer decoder: Some models implement referring segmentation using a pre-trained contrastive language-image pretraining (CLIP) encoder or training their own encoder. Trained on massive text corpora, their powerful natural language capabilities enable them to achieve zero-shot segmentation too. We explore these models in the next section.
Transformer encoder + CNN decoder: Some models like the segmentation transformer and TransUNet combine a transformer encoder with a CNN decoder, either for simplicity or for higher precision through CNN-based upsampling.
Language-Image Models for Referring Segmentation
The most impactful recent innovation in computer vision is the use of natural language to guide vision tasks, pioneered by OpenAI's CLIP and DALL-E. Segmentation, too, has benefited in the form of referring segmentation where natural language is used to guide the segmentation.
Some notable language-image models for semantic referring segmentation:
CLIPSeg: You can provide CLIPSeg with text queries or image queries for referring, zero-shot, or one-shot segmentation. We'll explore this model in depth in a later section.
GroupViT: GroupViT learns to hierarchically group regions into segments under text supervision.
SegCLIP: SegCLIP is conceptually similar to GroupViT in being able to assemble semantically related regions into segments.
Peekaboo: It adapts the stable diffusion generative model for unsupervised, zero-shot, semantic segmentation.
Vision Transformer Models for Any Image Segmentation
If you don't need natural language prompts, you can use one of the state-of-the-art vision-only unified architectures capable of all three segmentation tasks — semantic, instance, and panoptic:
EVA: EVA is a vanilla ViT that's pre-trained as a masked visual representation model and is capable of both semantic and instance segmentation, among many other downstream tasks. If you're familiar with BERT pre-training, think of EVA as the visual equivalent of BERT.
OneFormer: OneFormer is a unified model capable of semantic, instance, and panoptic segmentation.
Mask2Former: This unified model uses a special masked attention mechanism to achieve unified segmentation.
Next, we'll explore the CLIPSeg language-image architecture in depth.
CLIPSeg — CLIP for Text-Guided Zero-Shot and One-Shot Segmentation
CLIPSeg is a language-image semantic segmentation model that segments images based on your text prompts or example images. That means it's capable of one-shot and referring segmentation. Plus, its use of CLIP's powerful language model equips it for zero-shot segmentation, too. It's a straightforward and lightweight model, making it a good example of the language-image approach.
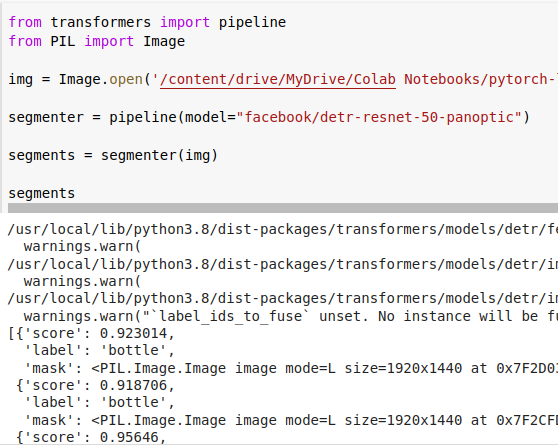
Real CLIPSeg Demo
For this demo, we asked CLIPSeg to segment an image according to two prompts — "orange bottles" and "boxes."
For the prompt "orange bottles," you can see how CLIPSeg segmented mostly just the orange bottles:
Segmentation for the prompt "orange bottles" (Original photo by Franki Chamaki on Unsplash)
For the prompt "boxes", it segments just the boxes in the bottom shelf:
CLIPSeg, too, uses an encoder-decoder architecture. Its encoder is just a pre-trained CLIP ViT-B/16 model. The decoder is a simple stack of just three standard transformer blocks to output an image-sized binary segment mask that isolates the matching class.
The inputs to the model are the target image and a segmentation class described either with a text prompt or an example image+mask whose analogy exists in the target image. A text prompt is converted into an embedding vector by CLIP's text encoder. An example image is converted into an embedding by CLIP's visual encoder. These embeddings are from CLIP's joint text-image embedding space.
To influence the segmentation, CLIPSeg uses two innovations. First, just like U-Net, its three decoder blocks have skip connections to three of the encoder's transformer blocks. They let the decoder use the encoder's attention activations to detect both nearby and distant regions of the same class.
The prompt influences the decoder's segment activations using feature-wise modulation (Source: Perez et al.)
The second innovation pertains to how it uses the input text or image prompt to activate specific regions. CLIPSeg uses the feature-wise linear modulation (FiLM) technique where the prompt's embeddings influence the decoder's input activations through a simple affine transform with two learnable parameters per feature. That's how the input text prompt or image prompt exerts influence on the decoder's segmentation outputs.
Through such simple ideas and architecture, CLIPSeg achieves zero-shot, one-shot, and referring segmentation. If its output masks are not precise enough for your requirements, you can add PointRend for more precise segmentation masks.
Multimodal Tracking Transformer for Text-Guided Video Instance Segmentation
Video segmentation is a very useful solution for video search and editing tasks in any industry. But it's a conceptually and computationally difficult problem because of the additional time axis and the volume of data. The possibility of users referring to actions and not just appearances adds to the complexity of text-guided video segmentation. However, the incredible power of transformers is set to revolutionize this area. The multimodal tracking transformer (MTTR) is one of the new models that can do text-guided instance segmentation on videos.
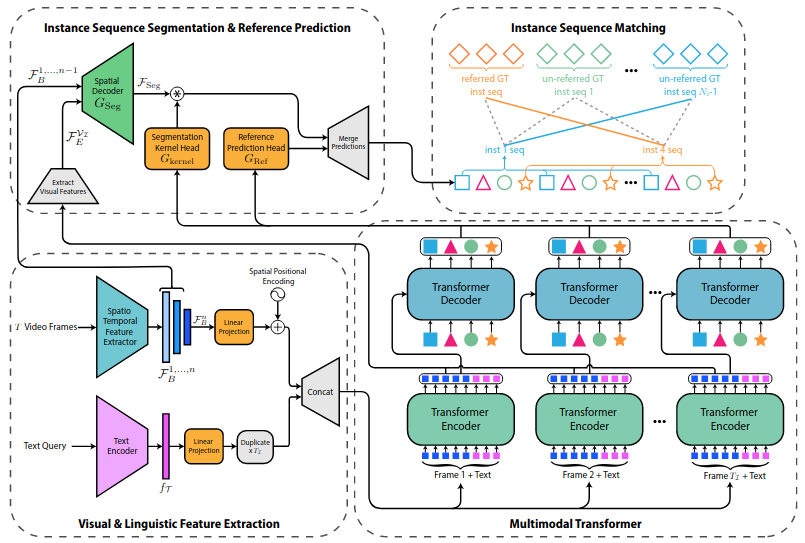
How Multimodal Tracking Transformer Works
Multimodal tracking transformer for video instance segmentation (Source: Botach et al.)
At a high level, it has a multimodal transformer network with an encoder and a decoder, a spatiotemporal feature extractor, a text feature extractor, and a segment voting module at the end that decides which output sequence best matches the text prompt.
MTTR extracts visual features from frames using a spatiotemporal encoder and text features from the text prompt using RoBERTa. From these features, the multimodal encoder produces a spatiotemporal representation of the video with information on which regions within and across frames are related to one another.
The multimodal decoder then uses that representation to generate several candidate sequences of segment predictions. Finally, the segment voting module identifies the segmentation sequence that best matches the text prompt and outputs its segmentation masks.
Hands-On Segmentation
In these sections, you'll learn the details about major deep-learning frameworks that are relevant to segmentation.
Using Hugging Face Transformers
Hugging Face transformers have extensive support for transformer-based segmentation, with features like:
Jupyter notebooks that demonstrate how to use these interfaces and models.
Using PyTorch
Torchvision gives you a set of pre-trained CNN models like FCN for semantic and mask R-CNN for instance segmentation. You can download more models from the PyTorch hub or Hugging Face. Useful utilities for manipulating and visualizing segmentation masks are also available.
Using TensorFlow
The TensorFlow ecosystem has many features for segmentation:
Official models and backbone networks like mask R-CNN and ViT
Detectron2 is Facebook's PyTorch-based framework and ecosystem that provides implementations for segmentation models like TensorMask, Panoptic-DeepLab, PointRend for precise segmentation, MaskFormer for unified segmentation, and BCNet for occlusion-aware instance segmentation.
Framework Recommendations
For transformer-based segmentation, you don't need to look beyond Hugging Face. Its capabilities and simplicity are far ahead of all the other choices. For CNN-based segmentation, TensorFlow's ecosystem has the most reliable and extensive set of models. If you want real-time segmentation on mobile phones, go with TensorFlow Lite or TensorFlow.js.
In our experience, Detectron2-based custom implementations were difficult to maintain because code changes to its interfaces or dependency upgrades between versions often broke code that previously worked.
Train a Custom Segmentation Model
Although zero-shot and unsupervised segmentation are gaining favor, real-world requirements like domain-specific prompts or low false positives may require you to train custom models from scratch or fine-tune existing models. In this section, you'll learn some essential information on training custom, supervised segmentation models.
Datasets
You normally train a system on an existing public dataset and then fine-tune it on your business-specific or task-specific proprietary dataset. Some essential public datasets you should know:
ADE20K has a large number of labeled indoor and outdoor scenes for instance and panoptic segmentation.
PhraseCut is a dataset of phrase-region pairs that you can use for fine-tuning CLIP-based or other referring segmentation models.
LAION-400M and LAION5B are massive datasets of text-image pairs for training CLIP-based or other referring segmentation models from scratch.
Plus, all the frameworks include some useful datasets.
Labeling Tools
For creating your custom datasets, you'll need some good labeling or annotation tools. Since segmentation masks are irregular, drawing them accurately can be time-consuming. That's why an ideal tool should have the following essential features:
Automatic shape estimation using segmentation algorithms or models
A contour editor with SVG support to let you easily refine the estimated shapes
Video frame labeling and object tracking across frames
Keyboard shortcuts and other productivity enhancements
Some good tools with these features are:
CVAT: CVAT is an open-source web application for image and video annotation. You can either self-host or use its paid online service.
Label Studio: Label Studio is another open-source web application that you can self-host or use as a paid cloud service.
Fine-Tuning
All the frameworks support fine-tuning pre-trained models. See Hugging Face's fine-tuning tutorial to learn how to train transformer-based PyTorch and TensorFlow models on your custom datasets.
Metrics
The common metrics for evaluating segmentation are the pixel-wise intersection-over-union (IoU), mean IoU, and mean average precision (mAP) calculated from the IoU. In addition, more specific metrics like IoU over foreground objects and IoU over background elements are also used.
Use Semantic Segmentation and Instance Segmentation in Your Business
The introduction of transformers to vision tasks has single-handedly advanced possibilities in just a few years. The breakthroughs in generative artificial intelligence like OpenAI's CLIP and GPT are also helping to improve vision tasks like segmentation. With years of experience in computer vision and natural language processing, we can assist you in introducing these capabilities to your business. Contact us to get started with these state of the art models.
References
Timo Lüddecke, Alexander S. Ecker (2021). "Image Segmentation Using Text and Image Prompts." arXiv:2112.10003 [cs.CV]. https://arxiv.org/abs/2112.10003
Ethan Perez, Florian Strub, Harm de Vries, Vincent Dumoulin, Aaron Courville (2017). "FiLM: Visual Reasoning with a General Conditioning Layer." arXiv:1709.07871 [cs.CV]. https://arxiv.org/abs/1709.07871
Adam Botach, Evgenii Zheltonozhskii, Chaim Baskin (2021). "End-to-End Referring Video Object Segmentation with Multimodal Transformers." arXiv:2111.14821 [cs.CV]. https://arxiv.org/abs/2111.14821v2
Jieneng Chen, Yongyi Lu, Qihang Yu, Xiangde Luo, Ehsan Adeli, Yan Wang, Le Lu, Alan L. Yuille, Yuyin Zhou (2021). "TransUNet: Transformers Make Strong Encoders for Medical Image Segmentation." arXiv:2102.04306 [cs.CV]. https://arxiv.org/abs/2102.04306
Bibek Aryal, Katie E. Miles, Sergio A. Vargas Zesati, Olac Fuentes (2023). "Boundary Aware U-Net for Glacier Segmentation." arXiv:2301.11454 [cs.CV]. https://arxiv.org/abs/2301.11454