How you can use machine learning based data matching to compare data features in a scalable architecture for deduping, record merging, and operational efficiency
Data matching is the workflow process of comparing different data values in structured or unstructured format based on similarity or an underlying entity. Similarity can mean whatever you want it to be based on your specific use case and what you define as an “entity”. Data matching has a bunch of advantages in the spaces of data cleansing, manual process automation, product market analysis, and sales intelligence. Companies with poor data workflows are shown to lose about 12% of their revenue because of data quality (it’s true!).
Old school data matching tools focus on using outdated methods such as rule based approaches and fuzzy matching. We’re going to look at how we use a custom machine learning pipeline to achieve better results that get even better over time with your data. Once you’ve used a machine learning based approach for data matching you’ll never go back to these old approaches.
What Is Data Matching? (With Machine Learning)
At a high level data matching is the process of comparing data such as product data, user data, customer data, etc based on similarity by some metric. There are many different types of data that can be compared for similarity with the most popular being product data matching. Different data matching software tools require different data points with some being able to decide similarity based on a product image + product title, and some tools allowing you to just use a single data point such as just product title. The main idea is to link different sets of data points based on several matching identifiers that are outlined.
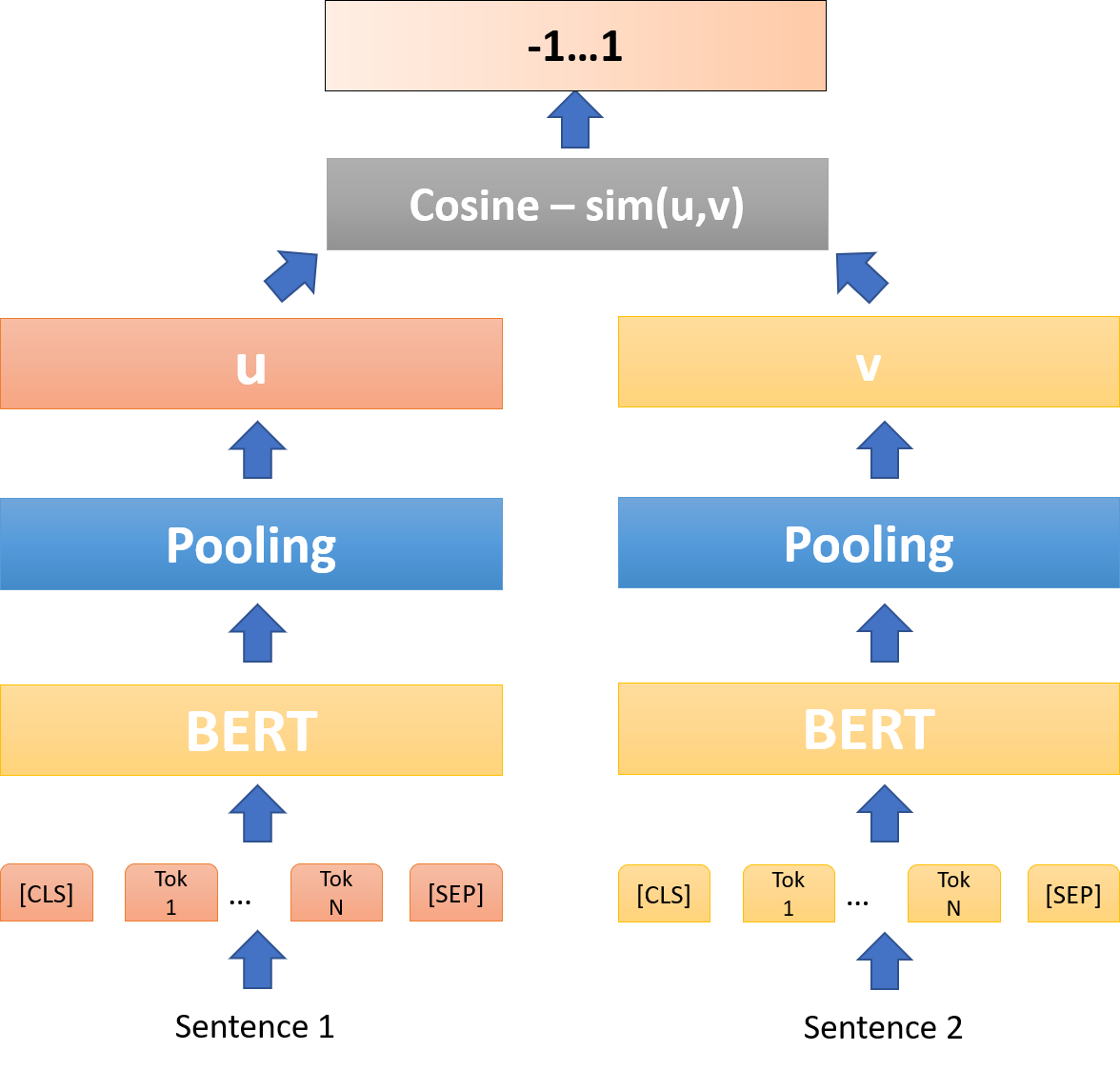
Data matching with machine learning is a powerful matching engine architecture built to leverage the learning capabilities of machine learning algorithms such as natural language processing, image similarity, linear combinators to match data on a deeper level. These pipelines learn a real relationship between the data you consider a match and what you don’t. We’ll see how this greatly outperforms the entity matching and fuzzy matching based products that constantly require tweaking and adjustments over time.
Product Title Matching With GPT-3
Why Use Machine Learning For Data Matching
Data matching with machine learning gives you a whole new level of flexibility in terms of a few key categories.
1 - We fine-tune the architecture for your specific use case which allows you to redefine what a “match” is. Since we’re matching based on similarity this can mean a bunch of different things in your backend system. Two matching SKUs, two UPC codes, integers exact or in a range - it’s completely up to you. We also have the flexibility to tune the architecture to use a wide range of data types including images, long integers, product descriptions, SSN numbers, you name it. We have the different machine learning algorithms in place to make the data matching software pipeline fit your data, as it should.
2 - These machine learning models use training and fine-tuning to learn a deeper relationship between your data and what is considered a match in a specific instance. This leads to matching that is much deeper than just high level entity pairing or fuzzy matching, both of which are not trained for your specific use case. The fine-tuning not only allows you to use data matching for more use cases, but reach a higher level of accuracy because the backbone models are now “focused” on only your use case. This means less edge cases and false positives break through, less adjustments need to be made throughout the life cycle of the product, and your model transitions to new data easier.
What’s the point in using data matching software if you have to change coded rules and parameters each time your data changes a bit? These pipelines have a much stronger relationship with your exact data and the backbone natural language processing or computer vision models are resilient enough to see through shifts in data over time. Let’s look at this real example:
We’re matching product UPC codes based on if the underlying SKU is the same. This is to clean up sales data records to understand the sales data for a specific SKU. The UPC codes come in as either full UPC codes or partial codes:
UPC code 1: 7-25272-73070-6
UPC code 2: 2527273070
These are both considered the same UPC code and are a match. Rules and fuzzy matching can do perfectly fine on this one.
UPC code 1: 725272730706
UPC code 2: 2527273070
UPC code 3: 1-725272730706-1
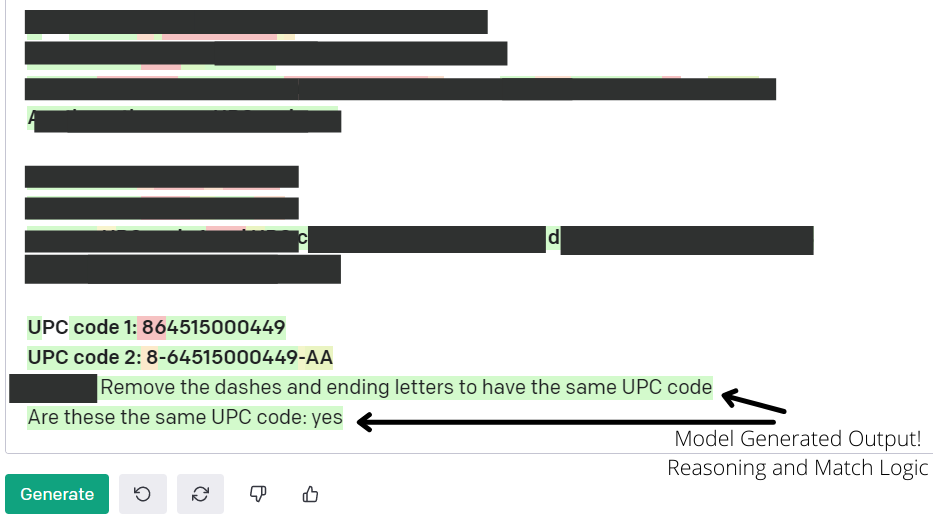
UPC code 1: 864515000449
UPC code 2: 8-64515000449-AA
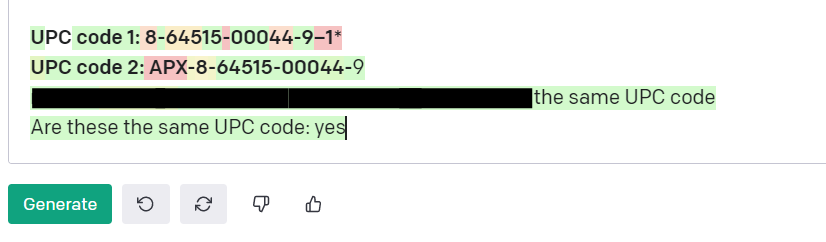
UPC code 3: 8-64515-00044-9–1*
UPC code 4: APX-8-64515-00044-
What happens if we increase the noise that the model must decipher to find a match between the same underlying UPC code? As you can see the original rules and fuzzy matching would have to be adjusted as our data variance grows. Machine learning based data matching learns the real relationship between the numbers and the sequences to know when to ignore noise why keeping the same baseline knowledge of what makes up a UPC code match. As you can imagine instances like these above come up all the time when adding new data sources, the data sources change format, the initial problem set changes. We don’t want to have to keep adjusting our data matching algorithm each time something like this happens. On top of that, our data matching software algorithm can use NLP to even tell you why something is a match or not!
NLP based same entity matching on UPC code
The data matching algorithms have never seen these UPC codes before and are matching them strictly on an understanding of what makes up a UPC code. There’s no rules or fuzzy matching going on, this is just natural language processing. We can provide the algorithm with any level of variation of data and cover it. That’s the power of machine learning based data matching.
Other Reasons To Use Machine Learning For Data Matching
Confidence scores can be generated along with the match result to let you know how confident the model is. This lets you use human intervention if you want to override some results or further break down the matching of a specific data field.
Fill in incomplete information in your data even with multiple sources.
You can use a wider range of data sources as usual noise does not affect the model once we’ve learned the data relationship. Multiple data sources actually helps the models long term matching data accuracy.
These tools improve over time as they get more comfortable with your exact data use case.
No matter if you’re using images, single digits, or huge product descriptions - machine learning can match it.
These matching algorithms can easily become an entry point to larger systems. Oftentimes data matching is used in things like anomaly detection, fraud detection, clustering, marketing intelligence, and other larger tasks. Matching incoming data is often the first step in many of these other machine learning systems.
Removing duplicate records is a popular use case for data matching software, and machine learning does this even better. Easily work towards removing incorrect data from your backend systems and improve database efficiency.
Data monitoring: Comparing data against a decided “correct” data set can allow you to deploy real time data monitoring fairly easily.
Imagine data similarity matching
Data Matching Software Examples For Use Cases With Different ML Tools
Let’s show a few of the many different ways you can use machine learning based data matching and what algorithms are used.
Matching Records Based On Just Product Title Using NLP
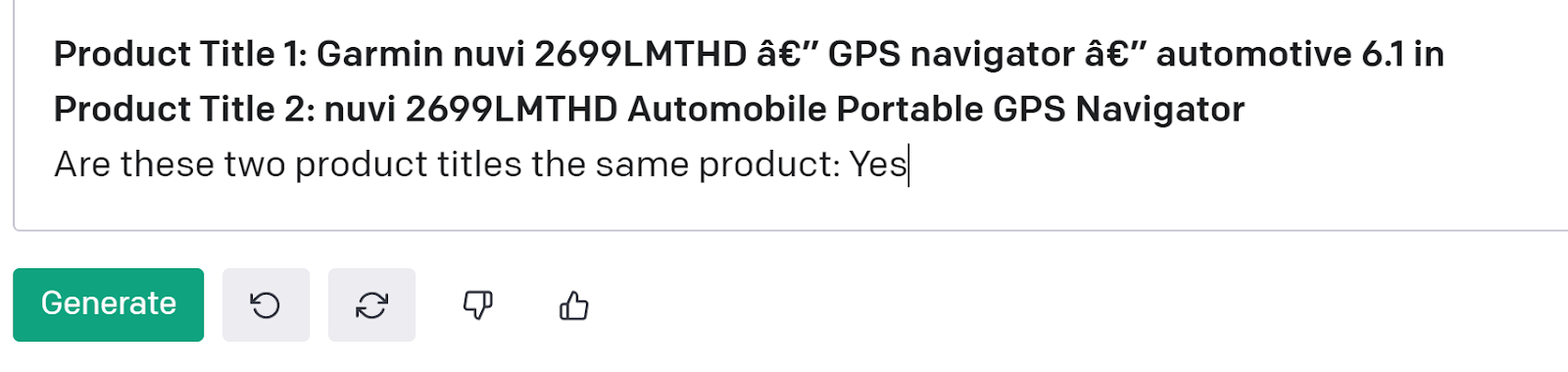
Using just the title of an ecommerce or retail product we can match data records that have the same underlying SKU. This architecture is trained to perform data matching with super high levels of noise, missing fields, and little standardization. The best part is this allows you to match an entity that could be made up of multiple columns (an entire product!) by just a single title.
Product Title Matching Model
Here we use GPT-3 as the baseline NLP model of the architecture, with a few other models sprinkled in throughout the pipeline to improve accuracy.
As we’ve seen before model generated output is unbolded by GPT-3
The amount of noise in the product titles that can be covered even at a baseline level is extremely high, and gets even higher when tuned for your use case. This example has no spaces between the name and bottle size, different bottle counts, and noise from another field on the end. As you can imagine it’s impossible to write rules that could imagine this level of noise. On top of that we get back easy to evaluate confidence metrics with GPT-3, and this one came back 87.40% confident in the result.
Want to see what’s under those boxes? Let’s schedule a demo today!
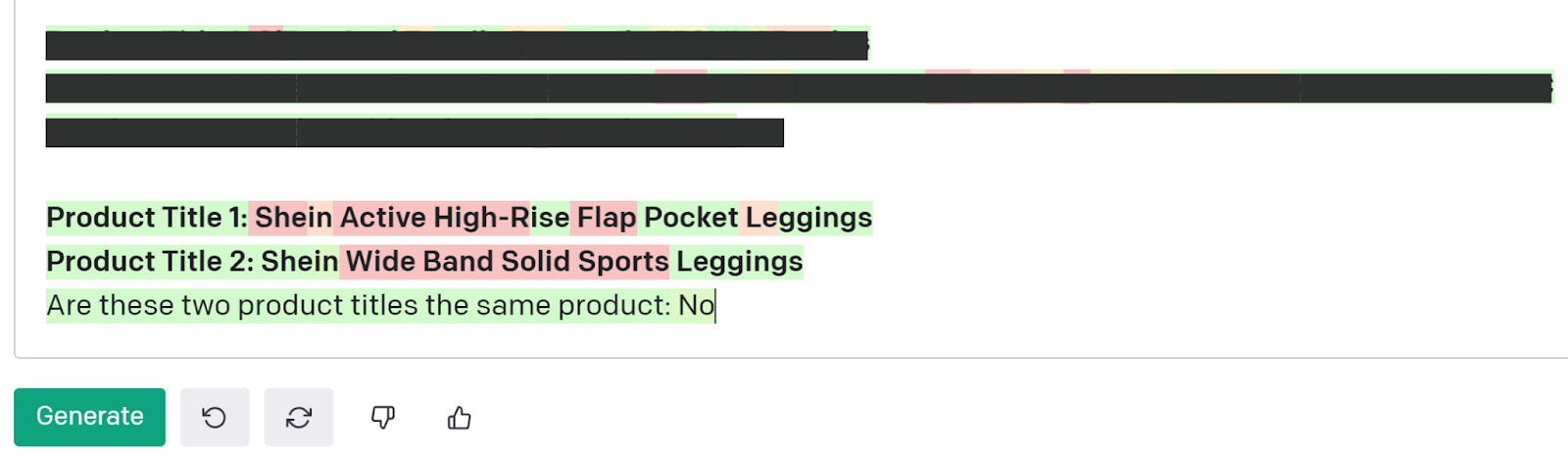
Completely different domain? No problem as our architecture still works its magic to tell that these two pairs of Shein leggings are not the same SKU. This time even more accurate as the confidence score is 88.08%!
Image Data Matching For Entity Resolution
By using deep learning based computer vision models we can directly compare database images for duplicate records. These images can be internal product images, competitor product images, or any other image data.
Your similar images can come from multiple databases or data sources as well.
These computer vision models learn how to recognize and extract features from images instead of the actual entity in the image. This allows you to deploy the architecture on any image dataset without needing to train on your specific data.
Image Data Matching Use Cases
This image similarity architecture can be used for any image data matching use case including:
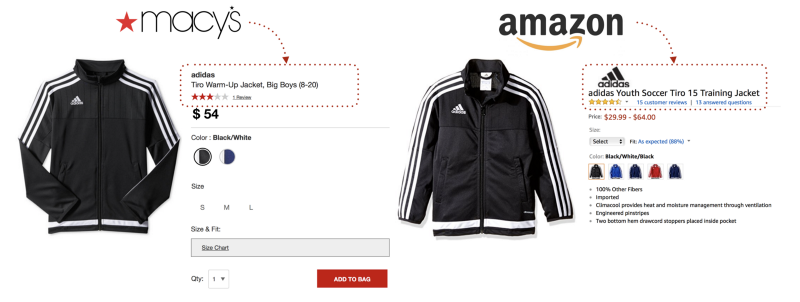
Product matching across different competitors to understand market size or price tracking. These two jackets would be incredibly difficult to compare just based on product attributes.
Track google images results for product design copyright infringement. This allows you to automatically track if competitors are stealing your designs or logos. In the image below think if we owned Starry Night and could search for it in images (right).
data quality checking where image similarity is just a piece of the larger architecture.
Removing duplicate data from our product image data. Multiple records with the same product image can affect our sales intelligence and cause errors.
General Text Field Matching
No matter the type of data used for a text field, machine learning based data matching tools can help you match these fields and link similar entities together. Whether it’s customer data short as names, or long form legal documents we can use deep learning pipelines to match to the same person or same document type. Fine-tuning these text field data matching tools allows us to quickly adjust to any use case and account for variation in string length.
Match medical records and medical data points to understand underlying data analytics.
Remove duplicate records from customer data fields such as phone number, email, name and more.
Match similar customer reviews to quickly understand how your business is viewed or remove duplicate reviews from the same customer.
Improve data accuracy & data quality of your sales and marketing intelligence tools.
Match fields with a mix of integers and string text.
Reduce storage utilization and network data transfer.
Improve any data enrichment pipelines to push forward your data driven business.
Example architecture to learn the relationship between two text fields. Sometimes we’ll build an architecture that leverages fuzzy matching as just a small piece of the puzzle.
Long Form Data Matching
We’ve matched documents over 25 pages and data entities with over 25 fields, no matter which one you’re looking for, our deep learning architectures can match them!
Product Data Matching Based On Long Form Description
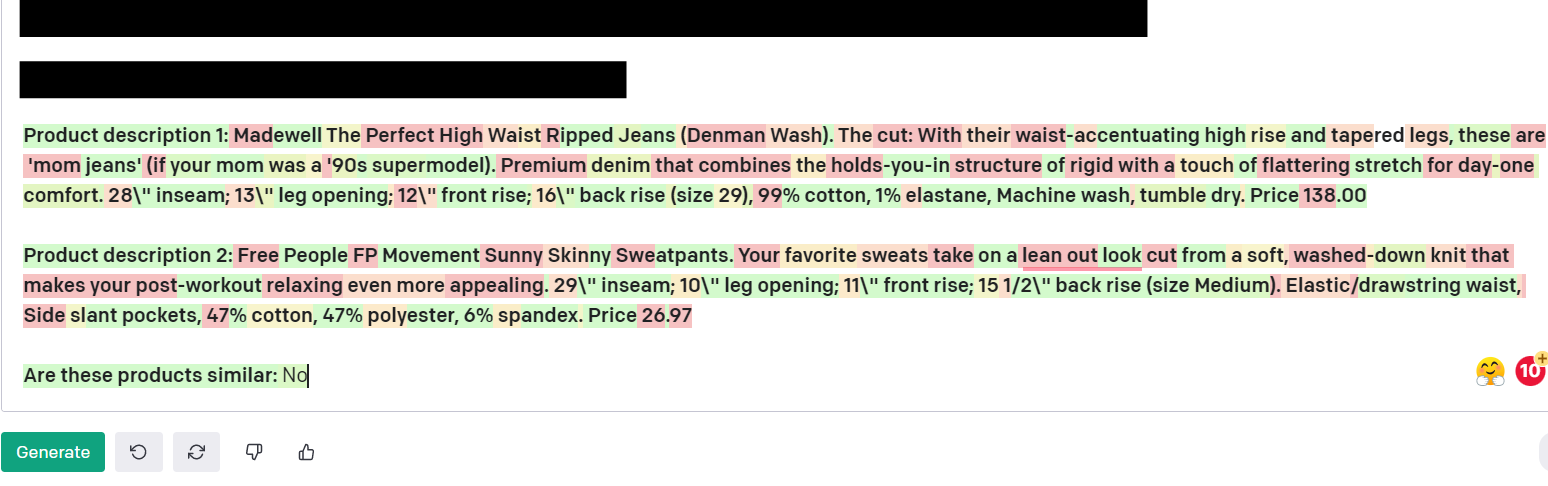
Using popular similarity models and large language models we can compare long form text fields to link exact or similar entities. This works on any long form text, and here we’re looking at comparing entire product descriptions to match similar products. This is also a great way to show how you can decide what “similarity” means for your use case! Before we saw using the underlying SKU as a match, and here we’re going to use a more relative “clothing type” match. This is a great way to compare products across competitors and get an understanding of the exact market.
Both are slim fit crewnecks!
Jeans vs Sweatpants
The model can also take variables such as price field, size field, and others into account.
How Does Product Description Data Matching Work?
Using the same NLP models outlined above we build an architecture that allows the models to learn a relationship between what leads to two data points being a match and two products not being a match. You have a level of control over what specifics generally lead to a match (name, price, keywords, etc) that you can’t get with more rigid approaches.
Multi Field Data Matching Tool
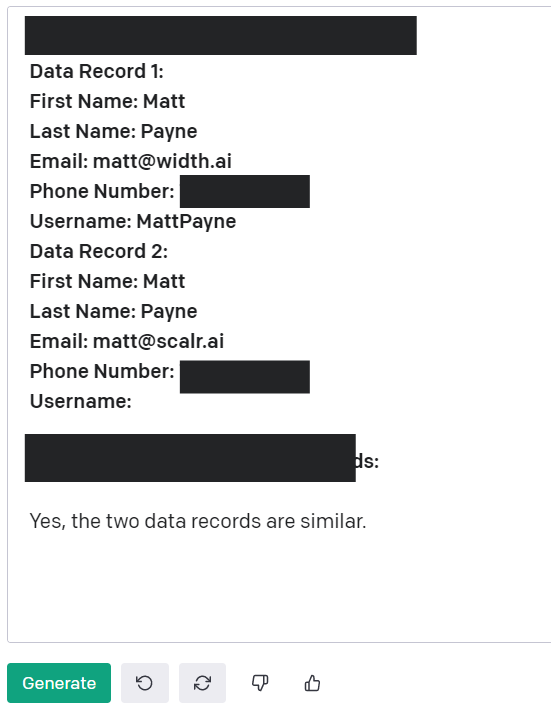
In many instances a single entity (or row) is made up of multiple data points from different fields. You can compare these individually to another set of multiple data points (first name to first name) or you can compare the entire row to an entire row (first name last name email to the same from another entity). Linking data fields together allows you to create a new equation for record matches. These architectures are usually much larger and incorporate more supervised learning than some of the other data matching methods described.
GPT-3 based version of this - where we have different emails and no username! As before the unbolded text is model output.
By using existing customer relationships between rows of customer data we can fine-tune our NLP architecture to link records.
Want To See Data Matching In Action?
Sign up for a demo today to see how our data matching solution can work in your organization. No matter the use case or data type we can use ai and deep learning today to match records at the highest matching accuracy in the industry. Let’s schedule a demo!