As the rise of few-shot learning with pretrained models as a way to work with data with few labels continues, companies are looking at ways to optimize this process by increasing accuracy and lower runtime, deployment, and training costs. Let’s take a look at the new architecture SetFit that shows serious results compared to other few shot learning models such as GPT-3 and T-FEW.
What is SetFit?
Before looking into the Sentence Transformer fine-tuning (SetFit) we need to quickly review an important area of Natural Language Processing (NLP) called few-shot learning.
Few-shot learning
Few-shot learning focuses on leveraging a few examples of how to complete a machine learning task to show a model how to complete this task on a new input. These methods deal with getting good performance results when a very limited amount of data is available by leveraging pre-trained large language models (LLMs) and prompt based programming.
This technique of learning from the data is highly sought because despite the fact that tons of text data is available free of cost and is easily accessible to us, annotating the data with high-quality labels requires a lot of human effort and comes with high costs in terms of time investment and money.
Text classification with few-shot learning is a technique focused on classifying text into any number of categories with very few examples of how to classify text provided for each class (or none at all for some classes). This is specifically useful for resource-constrained domains or for use cases when manual data labelling process is extremely expensive such as legal documents, financial documents, or long form documents.
Few shot text classification with a single box score example
Few-shot learning is a great way to get started with NLP tasks if quality data is a bottleneck. With that being said, the current few-shot learning workflows have a number of drawbacks that can make them difficult to use in a production setting.
There are a few key reasons that hinder the adoption of few-shot techniques in building production level systems-
Deploying Models: Deploying these LLMs on your own cloud infrastructure can be incredibly expensive. If you want full customization over your LLM you currently have to deploy an open source model (OPT, BLOOM, GPT-2) on your own infrastructure. This can require up to 8 GPUs and requires huge cloud infrastructure. If you use GPT-3 for your base LLM to skip the requirement of deploying your own model you have to pay per use and pay to fine-tune.
Fine-Tuning LLMs Cost Reasons: The existing methods for few-shot classification tasks require us to fine-tune very large pre-trained language models if we want to build systems that achieve high performance in terms of accuracy in NLP tasks. This requires a very large amount of computational resources (GPUs) for the training process, and for inference time processes.
For example, some of the popular large neural models and their estimated costs of training are as shown:
- GPT-3: ~$12 Million
- DALL-E: ~$500k- $1 million
- Stable Diffusion: ~$600k
Requirement of Prompts: Current techniques for few-shot based fine-tuning require handcrafted prompts to convert input data examples into a format that is suitable for the underlying large language model. These LLMs are task agnostic and use this task specific prompt learning and few-shot examples to understand the task you are trying to complete and how to reach a goal output. Building high-quality prompts in a few-shot environment can be extremely challenging for more complex tasks or tasks that contain a long-form input or output.
In the example of few-shot learning (FSL) based text classification our production results are mostly based on the data variance coverage we can reach in our prompt examples. As data variance grows from new training data or user inputs the models ability to leverage the few shot examples to correctly complete the task on a given input becomes much worse. There are a few techniques that can be used to help with this such as prompt optimization frameworks that turn baseline GPT-3 into in-context learning models as shown in our articles, but these don’t always solve the underlying problem.
In general, the style of manual prompt engineering can bring a lot of uncertainty in the results for most of the current few-shot learning techniques that are available. Moreover, generating handcrafted prompts requires a lot of effort on its own, to the extent that some FSL models like T-FEW even rely on “dataset-specific prompts” to perform well in practice.
To overcome these two bottlenecks this article talks about SetFit, which is a new architecture proposed by the research teams at Hugging Face with Intel labs and the UKP Lab that works to solve these two hurdles in the way of adopting FSL techniques, and also possesses manifold advantages over the existing techniques for few-shot learning tasks like prompt based GPT-3 and so on.
How SetFit works
SetFit uses rich text embeddings which removes the need for prompts (which also means more reliability and less variability in the predicted results - solves bottleneck 2), and is a very efficient framework for few-shot learning tasks requiring a much-labeled training data compared to the existing methods for the same tasks.
The diagram below compares SetFit with the other methods for classification using few-shot learning. SetFit requires significantly less number of train samples and still achieves better accuracy compared to the other techniques for few-shot learning.
SetFit using only 8 labeled examples per class on the Customer Reviews (CR) sentiment dataset gives results that are comparable to those of fine-tuning RoBERTa Large on the full training set of three thousand examples! It’s important to note that the fine-tuned RoBERTa is 3 times larger than the SetFit model used. Along with this, the uncertainty bands demonstrate better reliability (less uncertainty in terms of variability) in SetFit’s results. All of this with comparatively much smaller and cost-effective models!
Few shot classification benchmark vs RoBERTa with all examples
Key benefits of SetFit from the research paper:
The original research paper of SetFit unveiled many benefits over the current Few shot learning techniques. These benefits make SetFit a viable model for businesses and startups to deploy in multiple language applications.
Prompt-free design
SetFit is designed and based on the Sentence Transformers (STs) architecture which allows it to dispense with prompts altogether by virtue of rich text embeddings generated using fine-tuned Sentence Transformers. These rich sentence embedding vectors are further fed as input into a neural classifier head to classify text into one of the many classes. This is a key benefit of SetFit as although prompt engineering has its own benefits in terms of being able to leverage Masked Language Modelling as the training goal for all tasks, it is proved with experiments that the quality of prompts being used plays a significant role in the performance outputs of the models leading to very high variability in the predictions generated.
This can be challenging to use in a high data variance environment, and SetFit overcomes this by leveraging dense vector embeddings for sentences as a whole generated using fine-tuned STs, and thus SetFit’s results show lesser variability and more accuracy with a smaller amount of data needed. Apart from the metric point of view, this also saves the cost and labour involved in generating rich quality or model-specific prompts.
Cost and time benefits
SetFit does not require a pretrained LLM to achieve high accuracy, works with sentence transformers, and also requires very fewer data examples to be able to achieve prediction accuracies comparable to those achieved by large-scale models like T5 and GPT-3. This means for a similar (and in some cases better) level of performance, the training time for SetFit is an order of magnitude lesser comparatively, and therefore making it computationally less expensive as compared to GPT-3. To put into perspective GPT-3 vs SetFit, SetFit is 1,600 times smaller in size than GPT-3 and as well see shorty is able to beat it by impressive margins in multiple popular use cases. The same speed benefits can be seen during inference time as well, making it much easier for companies to leverage a LLM with efficient few-shot learning..
Easy multilingual ability
SetFit can be used with any of the available Sentence Transformers models on the Hugging Face Hub. This means SetFit supports the classification of text in not just English language but multiple languages. All that is required on our end is to simply fine-tune a multilingual checkpoint from the hub.
The original paper conducts experiments with SetFit over a range of different datasets and in multiple scenarios including distillation and non-English data. Setfit is compared to standard Pre-trained language model fine-tuning, state-of-the-art PET and PEFT-based methods such as ADAPET (2021) and T-FEW (2022) and even more interestingly to the recent prompt-free techniques such as PERFECT (2022).
To summarize the results from these experiments:
SETFIT’s performance when evaluated on a number of few-shot text classifications tasks shows that it outperforms the state-of-the-art prompt-free method and ranks alongside much larger prompt-based few-shot models. As an added benefit to this, SetFit now also supports multi-label text classification i.e. classification problems where a data point can belong to more than one class at a time.
SETFIT Architecture
Let’s take a look at some architectural details of SetFit and highlight the prime features that differentiate SetFit from other few-shot learning methods. Since SetFit works with a different type of transformer model called Sentence Transformers we’ll first understand how sentence transformers are trained and designed.
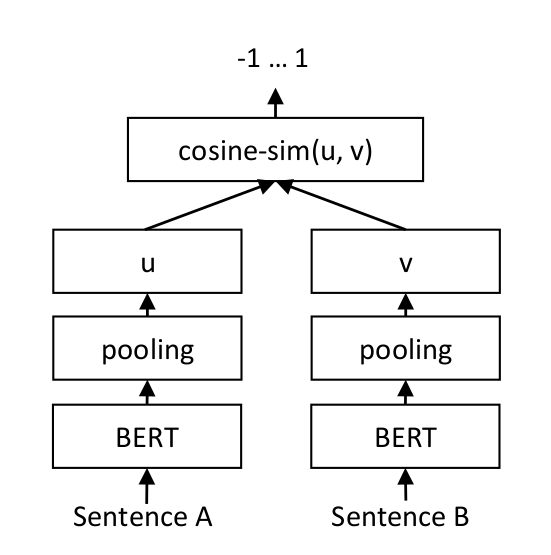
SetFiT is based on the Sentence Transformers architecture rather than vanilla transformers that use token embeddings. Sentence Transformers use Siamese networks and triplet network structures to modify the pre-trained transformer models in order to generate “semantically meaningful sentence embeddings”. The architecture works by Sentence Transformers generating embeddings for sentences as a whole (as compared to generating embeddings for tokens which is the case for vanilla transformer models) and the generated embeddings are semantically informed, i.e. the distance between pairs of semantically similar sentences is minimized and the distance between sentence pairs that are semantically distant is maximized. This is why Sentence Transformers are a way to generate dense vector representations of textual data.
As a mathematical implication of the kind of embeddings generated by Sentence transformer models, two sentences can be compared using cosine similarity to find a quantitative measure of how similar they are. These text embeddings generated using sentence transformers perform impressively for tasks involving semantic properties of sentences like semantic textual similarity, semantic search, or paraphrase mining. SetFit leverages these vector embeddings to represent the input data. It is important to note that the construction of vanilla transformer-based models like BERT, RoBERTa, etc makes them difficult to use for tasks like semantic similarity search as well as for unsupervised tasks like clustering, and hence STs work to solve the challenge of exploiting semantic properties of sentences.
Training of SetFit
The training design for SetFit exhibits a simple two-step strategy as is demonstrated in the figure below:
1. Sentence transformer fine-tuning
2. Classification head training.
Step 1: Sentence Transformer fine-tuning
Since the data available is limited, this step uses contrastive training to generate a much bigger dataset consisting of triplets coming from all classes in a text classification setting, where positive and negative pairs are created by an in-class and an out-class selection strategy, and the third entry in the triplet is the corresponding label. For in-class pairs the label is set to 1 to generate a triplet consisting of sentences coming from the same class. While for out-class pairs the label is set to 0 to generate a triplet consisting of sentences coming from different classes.
After this, a Sentence Transformer model is fine-tuned on these sentence pairs (or triplets) to generate dense vector representations.
Step 2: Classification head training
After the Sentence Transformer model is fine-tuned we use the original (limited) training data and generate sentence embeddings per training sample. These embeddings (as inputs) and the original class labels are now used as the dataset to train the classification head in the second step. A logistic regression model is used as the text classification head in the original research paper and architecture design.
Inference Time - How does SetFit work for generating predictions?
After training SetFit can be used for inference or generating predictions for a text classification NLP task in pretty much the same way. The fine-tuned Sentence Transformer model first generates an encoding vector for an unseen text input sentence and hence produces a sentence embedding for it. After this the logistic classification head that was trained in the training step is used to classify the input text by producing the class prediction of the input data based on its sentence embedding.
By just changing the underlying Sentence Transformer in the fine-tuning step, SetFit can be used for multiple languages including text classification in German, Japanese, Mandarin, French, and Spanish, in both in-language and cross-linguistic settings.
Benchmarking SetFit
In this section, we will demonstrate the practical value of using SetFit for business use cases by answering the following question -
How does SetFit fare in comparison to other few-shot learning methods?
First of all, let us compare SetFit with other models available for few-shot learning tasks to get an idea about how cost and compute-effective SetFit can be:
The table shows the model sizes in decreasing order of the number of parameters. SetFit is very small compared to the biggest model GPT-3 which contains a massive number of 175 Billion parameters. More parameters means a larger model which makes deployment, inference, and training more expensive and time consuming. While the tradeoff for larger models normally means higher accuracy and better data variance coverage, we can see below that SetFit performs exceptionally well on a number of tasks relative to the larger model competitors in a few-shot environment.
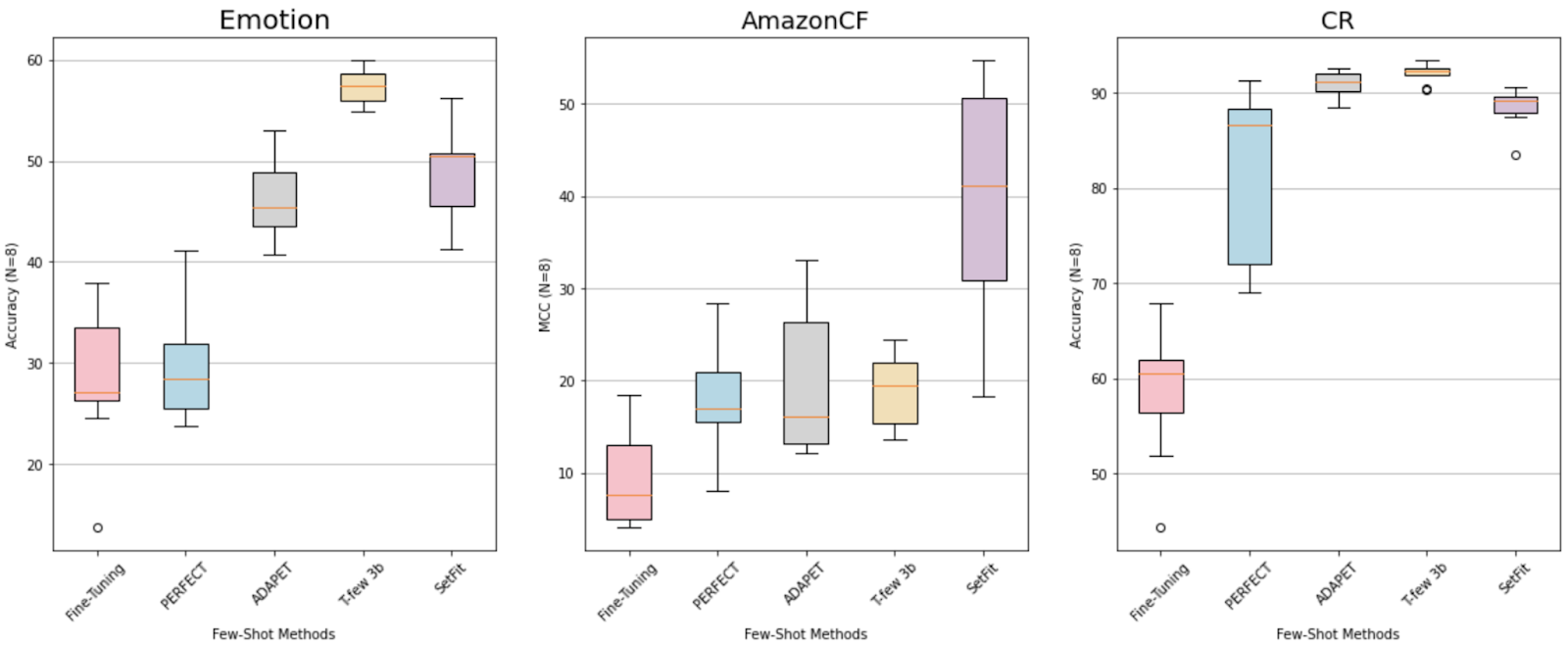
Let us first compare the performance of SetFit with other models for some standard datasets; we will be comparing SetFit with some baselines like PERFECT, ADAPET, and also with finetuning of standard transformers.
SetFit performance scores and standard deviation compared to baselines across 6 test datasets. Results from research paper (source)
Each table uses a different training set size (N=) where the first two are training samples per class and the last one is the entire training data set. SetFit achieves comparable results to the leader in each test dataset despite being significantly smaller. SetFit performs up to par with T-Few 3B in most categories and is 27x times smaller!
A box plot representation of the comparison of Setfit performance against other methods on 3 classification datasets is also shown below:
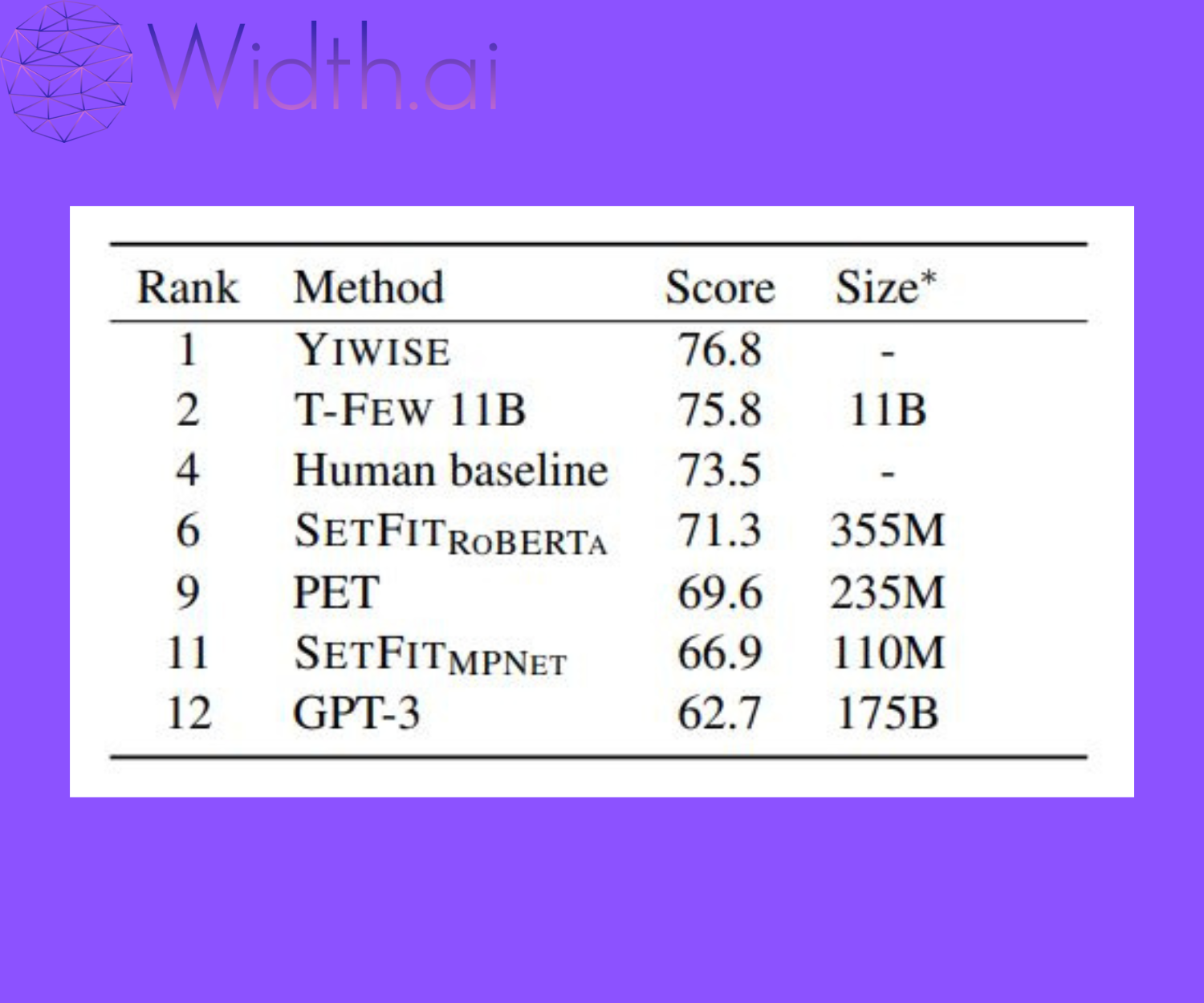
While till now we saw the results for standard datasets that are not specifically targeted at few-shot learning tasks, it is worth looking at the RAFT benchmark which is specifically designed for benchmarking few-shot methods. The following table shows the leaderboard performance of the different few-shot learning methods on the RAFT Benchmark (Results are as of September 2022).
Results from research paper (source). Even the human baseline is in reach of SetFit RoBERTa.
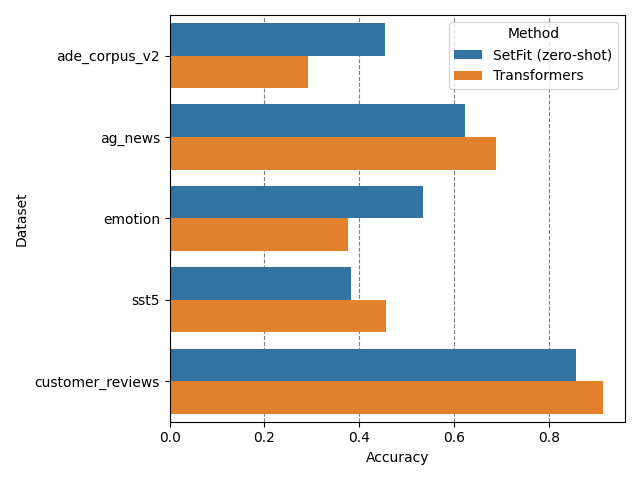
SetFit also supports zero-shot text classification and performs competitively (and sometimes outperforms) in comparison to the zero-shot pipeline in Transformers and is impressively 5-15 times faster! Here is a comparison of accuracy scores for classification in a zero-shot manner using SetFit vs zero-shot classification using Transformers.
The comparison is performed on standard datasets like SST-5, EMOTION, customer reviews, AG NEWS, and so on.
Fast training and inference
While performance during inference is often the most important metric businesses evaluate when designing production level systems, costs and latency issues are often considered when resources are more limited. For models with slow inference time this becomes an issue and hinders the adoption of state-of-the-art models into a production environment for most companies. SetFit has training and inference costs that are dramatically different from other models in the few-shot environment space. While this can partially be mapped to the reduced size of the model, we’ve seen above that this does not lead to lower accuracy in many use cases.
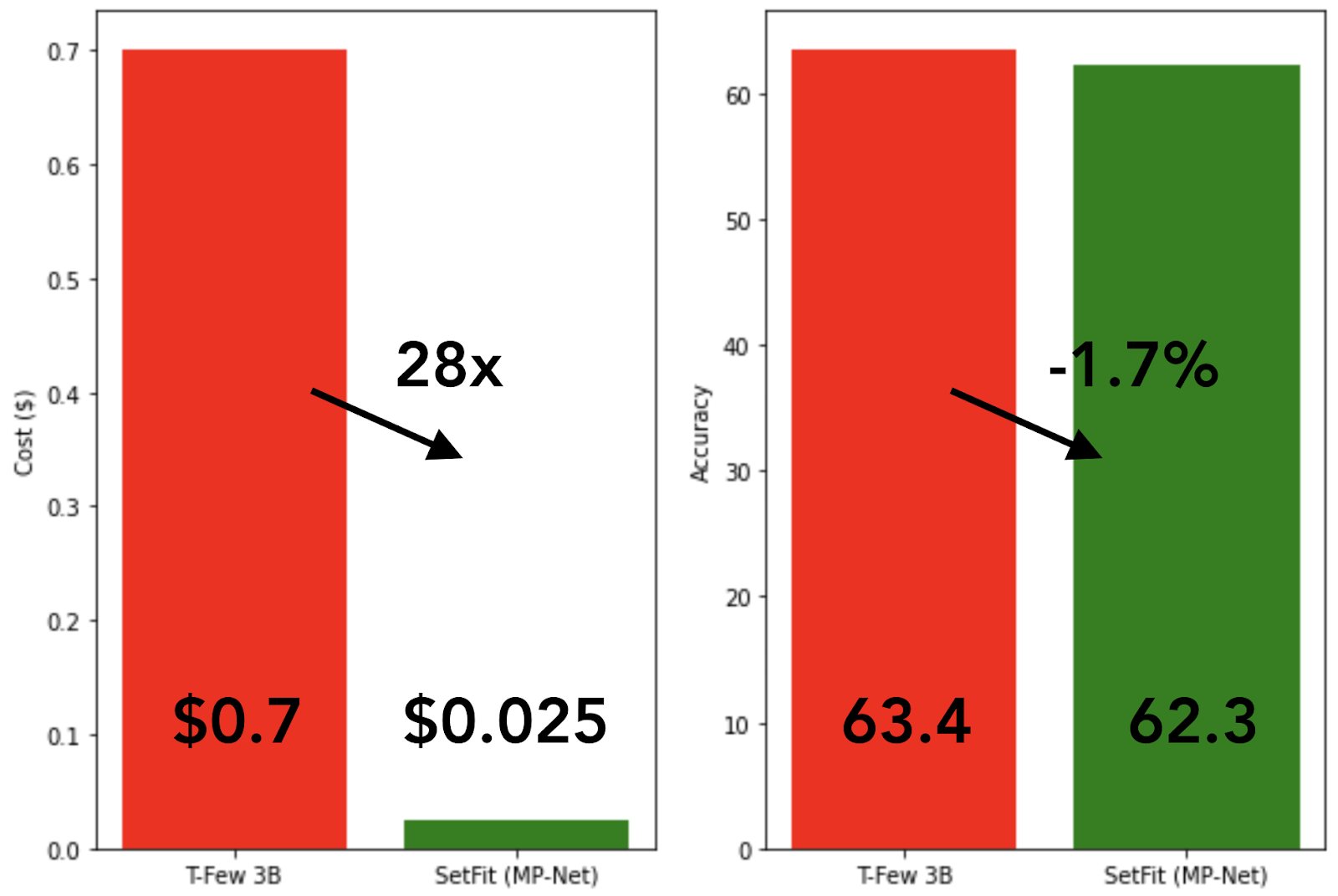
Comparing training cost and average performance for T-Few 3B and SetFit (MPNet), with 8 labeled examples per class.
Setfit is super fast and efficient to train with a competitive performance compared to larger models like GPT-3 and T-FEW. As we can see above the accuracy drop is only 1.7% with 28 times faster training time. This means you can train SetFit on an Nvidia V100 with 8 labelled examples per class in 30 seconds for a cost of $0.025. On the other hand, training T-Few 3B requires an NVIDIA A100 and takes “11 minutes”, at a cost of around $0.7 for the exact same experiment. 28 TIMES MORE!! SetFit can even run on a single GPU like the ones found on Google Colab notebooks. You can even train SetFit on CPU in just a few minutes. This is a huge boost for companies that have limited resources and still want to push out model versions in a fast paced ai development environment.
Comparison of distilled models
As we’ve seen, SetFit achieves upto-the-mark performance while being much smaller in size with much faster training and inference times. Through the use of model distillation we can achieve even smaller SetFit models to account for low data resource scenarios.
Previous experiments in Deep Learning research have shown model distillation to be an effective technique in reducing the computational load while preserving much of the original model’s performance. That said, the paper on SetFit also compares the performance of SetFit as a student model vs Transformers as a student model in a few-shot distillation setup with a limited amount of unlabelled training data at hand. Both student models have nearly the same size (15 m parameters) for a fair comparison in few-shot learning scenarios.
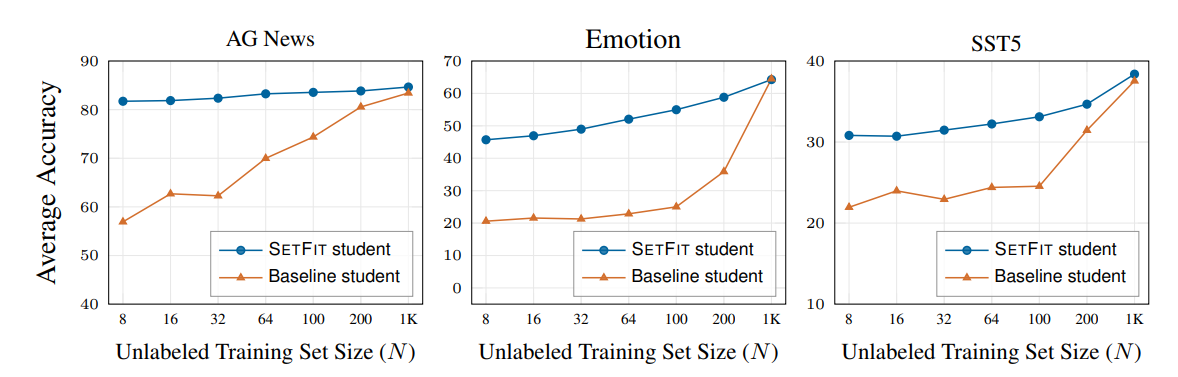
The graphical representation below shows the comparison of SetFit as a student model vs Transformers as a student model in terms of the accuracy vs the size of unlabeled training data. AG news, EMOTION, and SST- 5 datasets are compared and it is clearly evident that the SetFit student outperforms transformer-based student models for smaller datasets. Showing that even with distillation SetFit is a very efficient and high-performing few-shot learning technique relative to other models in various environments and resource constraints.
Want to get started with a custom SetFit model today?
Width.ai builds custom NLP software (just like this SetFit model) for businesses to leverage internally or as a part of their product. Schedule a call today and let’s talk about if SetFit is right for your use case or if a pretrained LLM would work better. Let’s Talk!